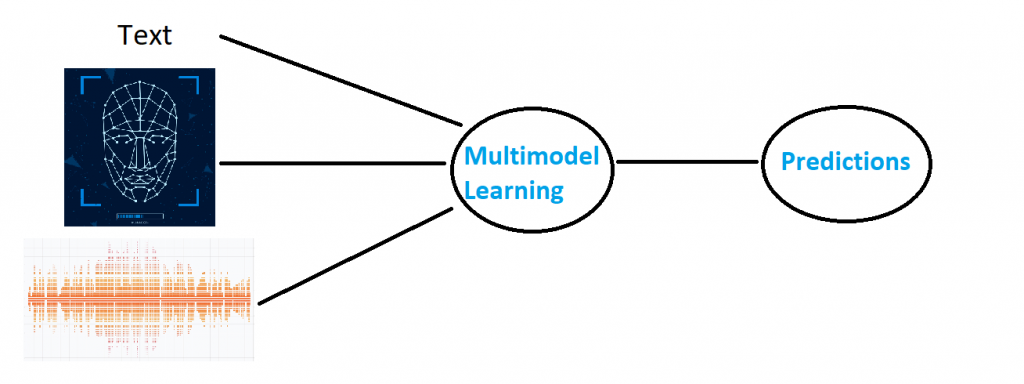

AI for Multimodal Learning
a. Single-Branch Networks for Multimodal Training
Related Publications
b Cross-Model Verification and Recognition
Related Publications
c. Multimedia Learning Using Conceptual Graph
Related Publications