
Research
1. Arif Mahmood, A Basit, M A Munir, M ALi, “Detection and Localization of Firearm Carriers in Complex Scenes for Improved Safety Measures”, accepted IEEE Transactions on Computational Social Systems (TCSS), Sep. 2023. (IF 5.0)
2. H Yaseen, Arif Mahmood, “Learning Structure Aware Deep Spectral Embedding”, accepted IEEE Transactions on Image Processing (TIP), May 2023. (IF 11.042)
3. M Z Zaheer, Arif Mahmood, M Astrid, S I Lee, “Clustering Aided Weakly Supervised Training to Detect Anomalous Events in Surveillance Videos”, accepted IEEE Transactions on Neural Networks and Learning Systems (TNNLS), May 2023. (IF 14.225)
4. S Javed, Arif Mahmood, T Qaiser, N Werghi, “Knowledge Distillation in Histology Landscape by Multi-Layer Features Supervision”, in IEEE Journal of Biomedical and Health Informatics (JBHI), April 2023. (IF 7.021)
5. S Aldhaheri, R Alotaibi, B Alzahrani, A Hadi, Arif Mahmood, A Alhothali, A Barnawi, “MACC Net: Multi-task attention crowd counting network”, in Applied Intelligence, 2023. (IF 5.019)
6. MS Saeed, S Nawaz, MH Khan, MZ Zaheer, K Nandakumar, MH Yousaf, Arif Mahmood, “Single- branch Network for Multimodal Training”, in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2023.
7. H Giraldo, S Javed, Arif Mahmood, F D Malliaros, T Bouwmans, “Higher-Order Sparse Convolutions in Graph Neural Networks”, in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2023.
8. Unsupervised Landmark Discovery Using Consistency-Guided Bottleneck, British Machine Vision Conference (BMVC) 2023.
1. Arif Mahmood, A Basit, M A Munir, M ALi, “Detection and Localization of Firearm Carriers in Complex Scenes for Improved Safety Measures”, accepted IEEE Transactions on Computational Social Systems (TCSS), Sep. 2023. (IF 5.0)
2. H Yaseen, Arif Mahmood, “Learning Structure Aware Deep Spectral Embedding”, accepted IEEE Transactions on Image Processing (TIP), May 2023. (IF 11.042)
3. M Z Zaheer, Arif Mahmood, M Astrid, S I Lee, “Clustering Aided Weakly Supervised Training to Detect Anomalous Events in Surveillance Videos”, accepted IEEE Transactions on Neural Networks and Learning Systems (TNNLS), May 2023. (IF 14.225)
4. S Javed, Arif Mahmood, T Qaiser, N Werghi, “Knowledge Distillation in Histology Landscape by Multi-Layer Features Supervision”, in IEEE Journal of Biomedical and Health Informatics (JBHI), April 2023. (IF 7.021)
5. S Aldhaheri, R Alotaibi, B Alzahrani, A Hadi, Arif Mahmood, A Alhothali, A Barnawi, “MACC Net: Multi-task attention crowd counting network”, in Applied Intelligence, 2023. (IF 5.019)
6. MS Saeed, S Nawaz, MH Khan, MZ Zaheer, K Nandakumar, MH Yousaf, Arif Mahmood, “Single- branch Network for Multimodal Training”, in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2023.
7. H Giraldo, S Javed, Arif Mahmood, F D Malliaros, T Bouwmans, “Higher-Order Sparse Convolutions in Graph Neural Networks”, in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2023.
8. Unsupervised Landmark Discovery Using Consistency-Guided Bottleneck, British Machine Vision Conference (BMVC) 2023.
1. Arif Mahmood, A Basit, M A Munir, M ALi, “Detection and Localization of Firearm Carriers in Complex Scenes for Improved Safety Measures”, accepted IEEE Transactions on Computational Social Systems (TCSS), Sep. 2023. (IF 5.0)
2. H Yaseen, Arif Mahmood, “Learning Structure Aware Deep Spectral Embedding”, accepted IEEE Transactions on Image Processing (TIP), May 2023. (IF 11.042)
3. M Z Zaheer, Arif Mahmood, M Astrid, S I Lee, “Clustering Aided Weakly Supervised Training to Detect Anomalous Events in Surveillance Videos”, accepted IEEE Transactions on Neural Networks and Learning Systems (TNNLS), May 2023. (IF 14.225)
4. S Javed, Arif Mahmood, T Qaiser, N Werghi, “Knowledge Distillation in Histology Landscape by Multi-Layer Features Supervision”, in IEEE Journal of Biomedical and Health Informatics (JBHI), April 2023. (IF 7.021)
5. S Aldhaheri, R Alotaibi, B Alzahrani, A Hadi, Arif Mahmood, A Alhothali, A Barnawi, “MACC Net: Multi-task attention crowd counting network”, in Applied Intelligence, 2023. (IF 5.019)
6. MS Saeed, S Nawaz, MH Khan, MZ Zaheer, K Nandakumar, MH Yousaf, Arif Mahmood, “Single- branch Network for Multimodal Training”, in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2023.
7. H Giraldo, S Javed, Arif Mahmood, F D Malliaros, T Bouwmans, “Higher-Order Sparse Convolutions in Graph Neural Networks”, in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2023.
8. Unsupervised Landmark Discovery Using Consistency-Guided Bottleneck, British Machine Vision Conference (BMVC) 2023.
1. Arif Mahmood, A Basit, M A Munir, M ALi, “Detection and Localization of Firearm Carriers in Complex Scenes for Improved Safety Measures”, accepted IEEE Transactions on Computational Social Systems (TCSS), Sep. 2023. (IF 5.0)
2. H Yaseen, Arif Mahmood, “Learning Structure Aware Deep Spectral Embedding”, accepted IEEE Transactions on Image Processing (TIP), May 2023. (IF 11.042)
3. M Z Zaheer, Arif Mahmood, M Astrid, S I Lee, “Clustering Aided Weakly Supervised Training to Detect Anomalous Events in Surveillance Videos”, accepted IEEE Transactions on Neural Networks and Learning Systems (TNNLS), May 2023. (IF 14.225)
4. S Javed, Arif Mahmood, T Qaiser, N Werghi, “Knowledge Distillation in Histology Landscape by Multi-Layer Features Supervision”, in IEEE Journal of Biomedical and Health Informatics (JBHI), April 2023. (IF 7.021)
5. S Aldhaheri, R Alotaibi, B Alzahrani, A Hadi, Arif Mahmood, A Alhothali, A Barnawi, “MACC Net: Multi-task attention crowd counting network”, in Applied Intelligence, 2023. (IF 5.019)
6. MS Saeed, S Nawaz, MH Khan, MZ Zaheer, K Nandakumar, MH Yousaf, Arif Mahmood, “Single- branch Network for Multimodal Training”, in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2023.
7. H Giraldo, S Javed, Arif Mahmood, F D Malliaros, T Bouwmans, “Higher-Order Sparse Convolutions in Graph Neural Networks”, in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2023.
8. Unsupervised Landmark Discovery Using Consistency-Guided Bottleneck, British Machine Vision Conference (BMVC) 2023.
1. Arif Mahmood, A Basit, M A Munir, M ALi, “Detection and Localization of Firearm Carriers in Complex Scenes for Improved Safety Measures”, accepted IEEE Transactions on Computational Social Systems (TCSS), Sep. 2023. (IF 5.0)
2. H Yaseen, Arif Mahmood, “Learning Structure Aware Deep Spectral Embedding”, accepted IEEE Transactions on Image Processing (TIP), May 2023. (IF 11.042)
3. M Z Zaheer, Arif Mahmood, M Astrid, S I Lee, “Clustering Aided Weakly Supervised Training to Detect Anomalous Events in Surveillance Videos”, accepted IEEE Transactions on Neural Networks and Learning Systems (TNNLS), May 2023. (IF 14.225)
4. S Javed, Arif Mahmood, T Qaiser, N Werghi, “Knowledge Distillation in Histology Landscape by Multi-Layer Features Supervision”, in IEEE Journal of Biomedical and Health Informatics (JBHI), April 2023. (IF 7.021)
5. S Aldhaheri, R Alotaibi, B Alzahrani, A Hadi, Arif Mahmood, A Alhothali, A Barnawi, “MACC Net: Multi-task attention crowd counting network”, in Applied Intelligence, 2023. (IF 5.019)
6. MS Saeed, S Nawaz, MH Khan, MZ Zaheer, K Nandakumar, MH Yousaf, Arif Mahmood, “Single- branch Network for Multimodal Training”, in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2023.
7. H Giraldo, S Javed, Arif Mahmood, F D Malliaros, T Bouwmans, “Higher-Order Sparse Convolutions in Graph Neural Networks”, in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2023.
8. Unsupervised Landmark Discovery Using Consistency-Guided Bottleneck, British Machine Vision Conference (BMVC) 2023.
1. Arif Mahmood, A Basit, M A Munir, M ALi, “Detection and Localization of Firearm Carriers in Complex Scenes for Improved Safety Measures”, accepted IEEE Transactions on Computational Social Systems (TCSS), Sep. 2023. (IF 5.0)
2. H Yaseen, Arif Mahmood, “Learning Structure Aware Deep Spectral Embedding”, accepted IEEE Transactions on Image Processing (TIP), May 2023. (IF 11.042)
3. M Z Zaheer, Arif Mahmood, M Astrid, S I Lee, “Clustering Aided Weakly Supervised Training to Detect Anomalous Events in Surveillance Videos”, accepted IEEE Transactions on Neural Networks and Learning Systems (TNNLS), May 2023. (IF 14.225)
4. S Javed, Arif Mahmood, T Qaiser, N Werghi, “Knowledge Distillation in Histology Landscape by Multi-Layer Features Supervision”, in IEEE Journal of Biomedical and Health Informatics (JBHI), April 2023. (IF 7.021)
5. S Aldhaheri, R Alotaibi, B Alzahrani, A Hadi, Arif Mahmood, A Alhothali, A Barnawi, “MACC Net: Multi-task attention crowd counting network”, in Applied Intelligence, 2023. (IF 5.019)
6. MS Saeed, S Nawaz, MH Khan, MZ Zaheer, K Nandakumar, MH Yousaf, Arif Mahmood, “Single- branch Network for Multimodal Training”, in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2023.
7. H Giraldo, S Javed, Arif Mahmood, F D Malliaros, T Bouwmans, “Higher-Order Sparse Convolutions in Graph Neural Networks”, in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2023.
8. Unsupervised Landmark Discovery Using Consistency-Guided Bottleneck, British Machine Vision Conference (BMVC) 2023.
1. Arif Mahmood, A Basit, M A Munir, M ALi, “Detection and Localization of Firearm Carriers in Complex Scenes for Improved Safety Measures”, accepted IEEE Transactions on Computational Social Systems (TCSS), Sep. 2023. (IF 5.0)
2. H Yaseen, Arif Mahmood, “Learning Structure Aware Deep Spectral Embedding”, accepted IEEE Transactions on Image Processing (TIP), May 2023. (IF 11.042)
3. M Z Zaheer, Arif Mahmood, M Astrid, S I Lee, “Clustering Aided Weakly Supervised Training to Detect Anomalous Events in Surveillance Videos”, accepted IEEE Transactions on Neural Networks and Learning Systems (TNNLS), May 2023. (IF 14.225)
4. S Javed, Arif Mahmood, T Qaiser, N Werghi, “Knowledge Distillation in Histology Landscape by Multi-Layer Features Supervision”, in IEEE Journal of Biomedical and Health Informatics (JBHI), April 2023. (IF 7.021)
5. S Aldhaheri, R Alotaibi, B Alzahrani, A Hadi, Arif Mahmood, A Alhothali, A Barnawi, “MACC Net: Multi-task attention crowd counting network”, in Applied Intelligence, 2023. (IF 5.019)
6. MS Saeed, S Nawaz, MH Khan, MZ Zaheer, K Nandakumar, MH Yousaf, Arif Mahmood, “Single- branch Network for Multimodal Training”, in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2023.
7. H Giraldo, S Javed, Arif Mahmood, F D Malliaros, T Bouwmans, “Higher-Order Sparse Convolutions in Graph Neural Networks”, in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2023.
8. Unsupervised Landmark Discovery Using Consistency-Guided Bottleneck, British Machine Vision Conference (BMVC) 2023.
1. Arif Mahmood, A Basit, M A Munir, M ALi, “Detection and Localization of Firearm Carriers in Complex Scenes for Improved Safety Measures”, accepted IEEE Transactions on Computational Social Systems (TCSS), Sep. 2023. (IF 5.0)
2. H Yaseen, Arif Mahmood, “Learning Structure Aware Deep Spectral Embedding”, accepted IEEE Transactions on Image Processing (TIP), May 2023. (IF 11.042)
3. M Z Zaheer, Arif Mahmood, M Astrid, S I Lee, “Clustering Aided Weakly Supervised Training to Detect Anomalous Events in Surveillance Videos”, accepted IEEE Transactions on Neural Networks and Learning Systems (TNNLS), May 2023. (IF 14.225)
4. S Javed, Arif Mahmood, T Qaiser, N Werghi, “Knowledge Distillation in Histology Landscape by Multi-Layer Features Supervision”, in IEEE Journal of Biomedical and Health Informatics (JBHI), April 2023. (IF 7.021)
5. S Aldhaheri, R Alotaibi, B Alzahrani, A Hadi, Arif Mahmood, A Alhothali, A Barnawi, “MACC Net: Multi-task attention crowd counting network”, in Applied Intelligence, 2023. (IF 5.019)
6. MS Saeed, S Nawaz, MH Khan, MZ Zaheer, K Nandakumar, MH Yousaf, Arif Mahmood, “Single- branch Network for Multimodal Training”, in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2023.
7. H Giraldo, S Javed, Arif Mahmood, F D Malliaros, T Bouwmans, “Higher-Order Sparse Convolutions in Graph Neural Networks”, in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2023.
8. Unsupervised Landmark Discovery Using Consistency-Guided Bottleneck, British Machine Vision Conference (BMVC) 2023.
1. Arif Mahmood, A Basit, M A Munir, M ALi, “Detection and Localization of Firearm Carriers in Complex Scenes for Improved Safety Measures”, accepted IEEE Transactions on Computational Social Systems (TCSS), Sep. 2023. (IF 5.0)
2. H Yaseen, Arif Mahmood, “Learning Structure Aware Deep Spectral Embedding”, accepted IEEE Transactions on Image Processing (TIP), May 2023. (IF 11.042)
3. M Z Zaheer, Arif Mahmood, M Astrid, S I Lee, “Clustering Aided Weakly Supervised Training to Detect Anomalous Events in Surveillance Videos”, accepted IEEE Transactions on Neural Networks and Learning Systems (TNNLS), May 2023. (IF 14.225)
4. S Javed, Arif Mahmood, T Qaiser, N Werghi, “Knowledge Distillation in Histology Landscape by Multi-Layer Features Supervision”, in IEEE Journal of Biomedical and Health Informatics (JBHI), April 2023. (IF 7.021)
5. S Aldhaheri, R Alotaibi, B Alzahrani, A Hadi, Arif Mahmood, A Alhothali, A Barnawi, “MACC Net: Multi-task attention crowd counting network”, in Applied Intelligence, 2023. (IF 5.019)
6. MS Saeed, S Nawaz, MH Khan, MZ Zaheer, K Nandakumar, MH Yousaf, Arif Mahmood, “Single- branch Network for Multimodal Training”, in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2023.
7. H Giraldo, S Javed, Arif Mahmood, F D Malliaros, T Bouwmans, “Higher-Order Sparse Convolutions in Graph Neural Networks”, in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2023.
8. Unsupervised Landmark Discovery Using Consistency-Guided Bottleneck, British Machine Vision Conference (BMVC) 2023.
1. Arif Mahmood, A Basit, M A Munir, M ALi, “Detection and Localization of Firearm Carriers in Complex Scenes for Improved Safety Measures”, accepted IEEE Transactions on Computational Social Systems (TCSS), Sep. 2023. (IF 5.0)
2. H Yaseen, Arif Mahmood, “Learning Structure Aware Deep Spectral Embedding”, accepted IEEE Transactions on Image Processing (TIP), May 2023. (IF 11.042)
3. M Z Zaheer, Arif Mahmood, M Astrid, S I Lee, “Clustering Aided Weakly Supervised Training to Detect Anomalous Events in Surveillance Videos”, accepted IEEE Transactions on Neural Networks and Learning Systems (TNNLS), May 2023. (IF 14.225)
4. S Javed, Arif Mahmood, T Qaiser, N Werghi, “Knowledge Distillation in Histology Landscape by Multi-Layer Features Supervision”, in IEEE Journal of Biomedical and Health Informatics (JBHI), April 2023. (IF 7.021)
5. S Aldhaheri, R Alotaibi, B Alzahrani, A Hadi, Arif Mahmood, A Alhothali, A Barnawi, “MACC Net: Multi-task attention crowd counting network”, in Applied Intelligence, 2023. (IF 5.019)
6. MS Saeed, S Nawaz, MH Khan, MZ Zaheer, K Nandakumar, MH Yousaf, Arif Mahmood, “Single- branch Network for Multimodal Training”, in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2023.
7. H Giraldo, S Javed, Arif Mahmood, F D Malliaros, T Bouwmans, “Higher-Order Sparse Convolutions in Graph Neural Networks”, in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2023.
8. Unsupervised Landmark Discovery Using Consistency-Guided Bottleneck, British Machine Vision Conference (BMVC) 2023.
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
CPLIP: Zero-Shot Learning for Histopathology with Comprehensive Vision-Language Alignment (IEEE/CVF CVPR , 2024)
Abstract:
Model Diagram
Paper Link:
Citation:
@INPROCEEDINGS{sajid2024cplip,
title={CPLIP: Zero-Shot Learning for Histopathology with Comprehensive Vision-Language Alignment},
author={Sajid Javed, Arif Mahmood, Iyyakutti Iyappan Ganapathi, Fayaz Ali Dharejo1, Naoufel Werghi, Mohammed Bennamoun},
booktitle = {IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)}
year={2024}
}
DiffuseMix: Label-Preserving Data Augmentation with Diffusion Models (IEEE/CVF CVPR , 2024)
Abstract:
Model Diagram
Paper Link:
Citation:
@INPROCEEDINGS{diffuseMix2024,
title={DiffuseMix: Label-Preserving Data Augmentation with Diffusion Models},
author={Khawar Islam, Muhammad Zaigham Zaheer, Arif Mahmood, Karthik Nandakumar},
booktitle = {IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2024}}
Pose-Guided Self-Training with Two-Stage Clustering for Unsupervised Landmark Discovery (IEEE/CVF CVPR , 2024)
Abstract:
Model Diagram

Paper Link:
Citation:
@INPROCEEDINGS{DULD2024,
title={Pose-Guided Self-Training with Two-Stage Clustering for Unsupervised Landmark Discovery},
author={S Tourani, A Alwheibi, Arif Mahmood, M H Khan},
booktitle = {IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2024}}
Generative Cooperative Learning for Unsupervised Video Anomaly Detection (IEEE/CVF CVPR , 2022)
Abstract:
Model Diagram
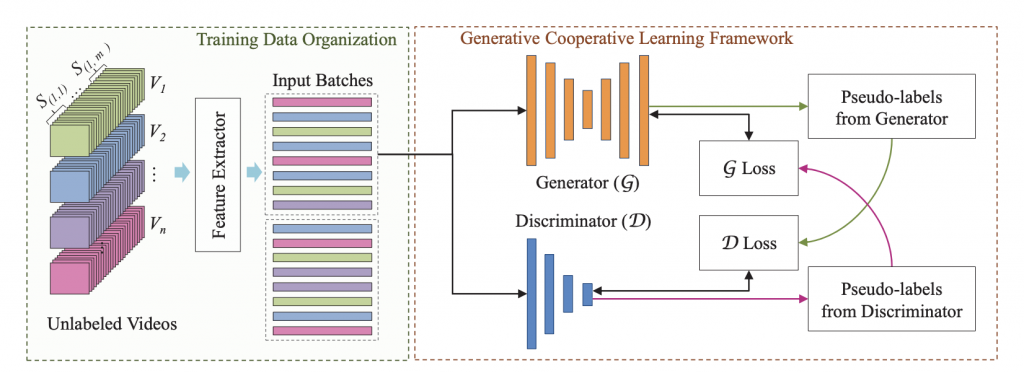
Paper Link:
Citation:
@inproceedings{GCL2022,
title={Generative Cooperative Learning for Unsupervised Video Anomaly Detection},
author={M Z Zaheer, Arif Mahmood, M. H. Khan, M Segu, F Yu, S Lee},
booktitle={IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2022}}
Semi-supervised Spectral Clustering for Image Set Classification (IEEE/CVF CVPR, 2014)
Abstract:
Model Diagram
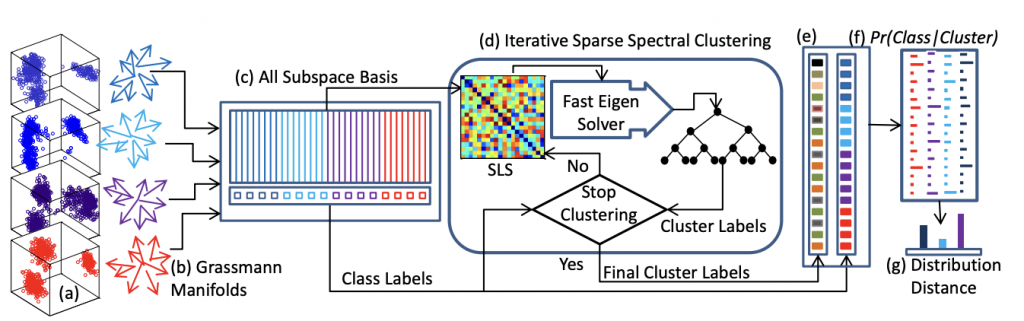
Paper Link:
Citation:
@INPROCEEDINGS {6909417,
author = {Arif Mahmood and A. Mian and R. Owens},
booktitle = {2014 IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
title = {Semi-supervised Spectral Clustering for Image Set Classification},
year = {2014},
issn = {1063-6919},
pages = {121-128}}
European Conference on Computer Vision (ECCV)
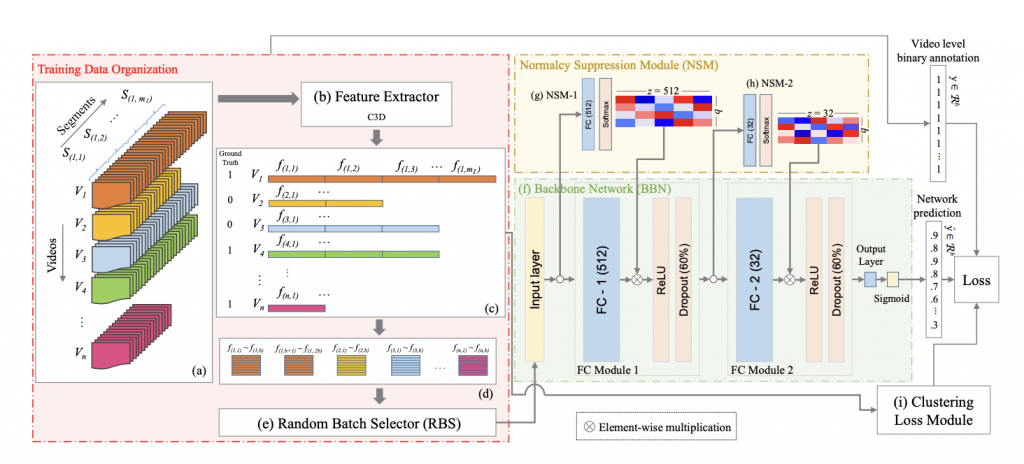
CLAWS: Clustering Assisted Weakly Supervised Learning with Normalcy Suppression for Anomalous Event Detection (ECCV, 2021)
Abstract:
Model Diagram
Paper Link:
Citation:
@inproceedings{zaheer2020claws,
title={CLAWS: Clustering Assisted Weakly Supervised Learning with Normalcy Suppression for Anomalous Event Detection},
author={Zaheer, Muhammad Zaigham and Mahmood, Arif and Astrid, Marcella and Lee, Seung-Ik},
booktitle={European Conference on Computer Vision},
pages={358–376},
year={2020},
organization={Springer}}
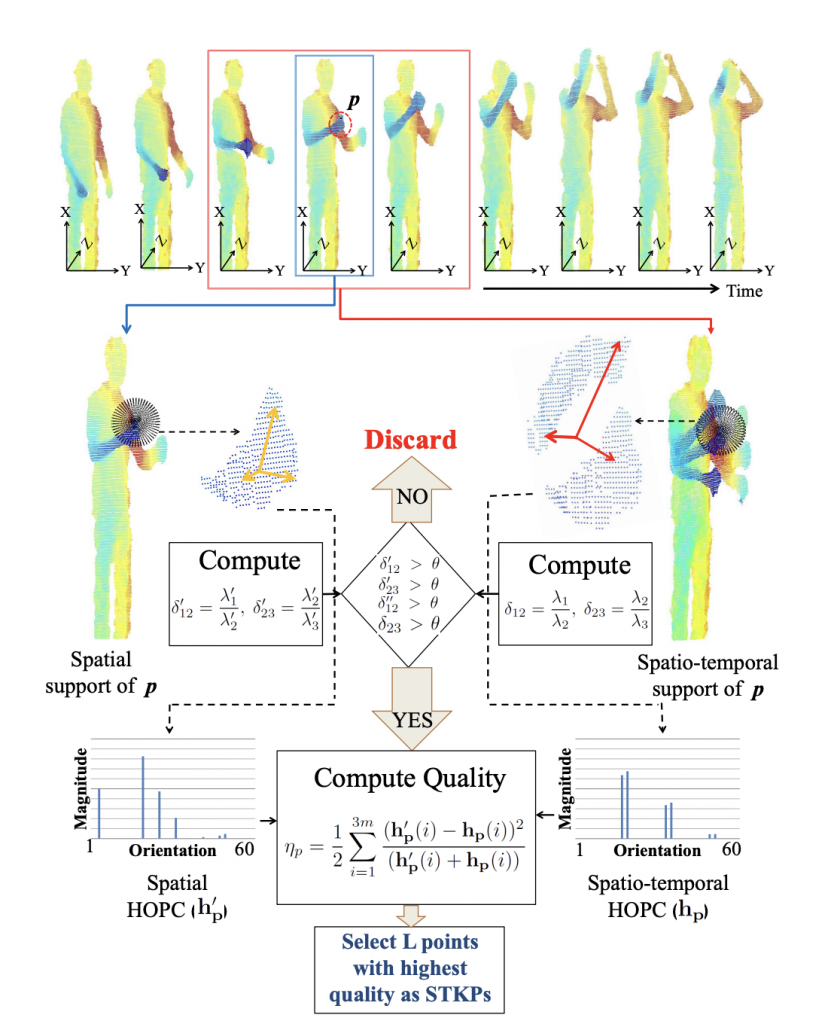
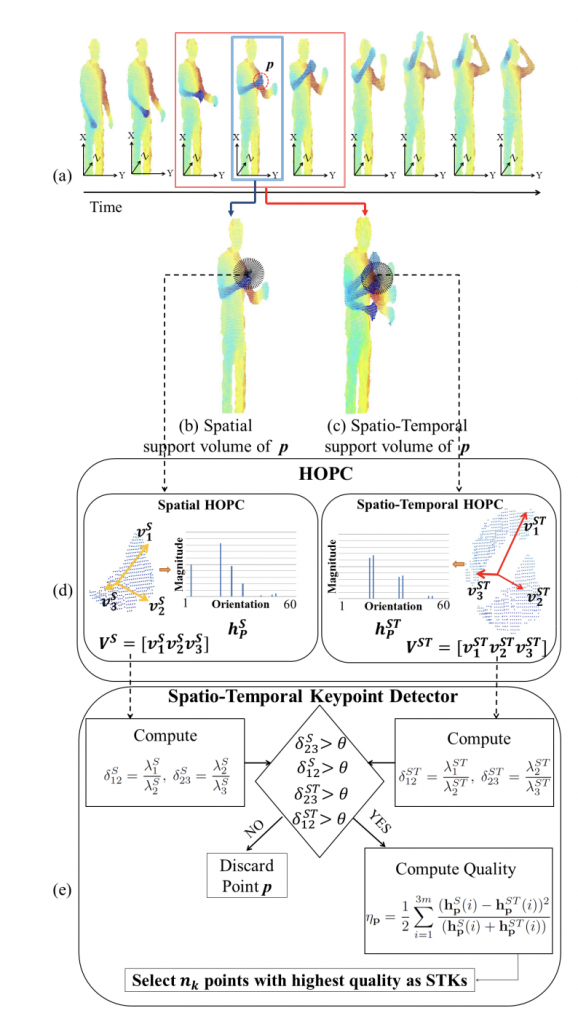
HOPC: Histogram of oriented principal components of 3D point clouds for action recognition (ECCV, 2014)
Abstract:
Existing techniques for 3D action recognition are sensitive to viewpoint variations because they extract features from depth images which change significantly with viewpoint. In contrast, we directly process the point clouds and propose a new technique for action recognition which is more robust to noise, action speed and viewpoint variations. Our technique consists of a novel descriptor and keypoint detection algorithm. The proposed descriptor is extracted at a point by encoding the Histogram of Oriented Principal Components (HOPC) within an adaptive spatio-temporal support volume around that point. Based on this descriptor, we present a novel method to detect Spatio-Temporal Key-Points (STKPs) in 3D point cloud sequences. Experimental results show that the proposed descriptor and STKP detector outperform state-of-the-art algorithms on three benchmark human activity datasets. We also introduce a new multiview public dataset and show the robustness of our proposed method to viewpoint variations.
Model Diagram
Paper Link:
Citation:
@inproceedings{rahmani2014hopc,
title={HOPC: Histogram of oriented principal components of 3D point clouds for action
recognition},
author={Rahmani, Hossein and Mahmood, Arif and Q Huynh, Du and Mian, Ajmal},
booktitle={European Conference on Computer Vision},
pages={742–757},
year={2014},
organization={Springer}}
British Machine Vision Conference (BMVC)
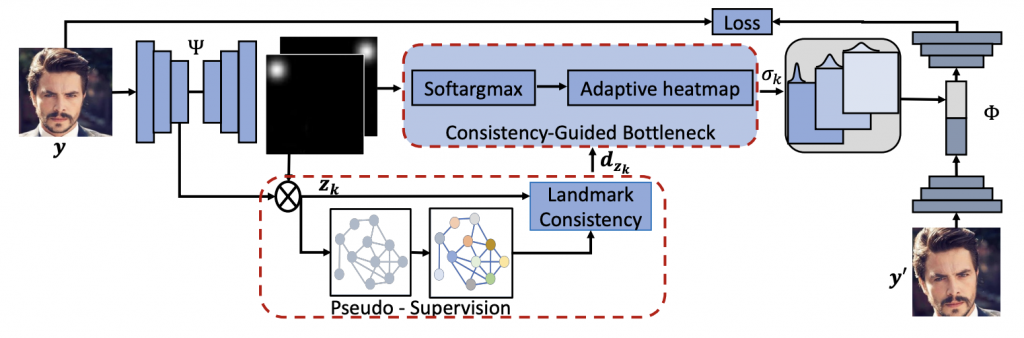
Unsupervised Landmark Discovery Using Consistency-Guided Bottleneck (BMVC, 2023)
Abstract:
We study a challenging problem of unsupervised discovery of object landmarks. Many recent methods rely on bottlenecks to generate 2D Gaussian heat maps however, these are limited in generating informed heatmaps while training, presumably due to the lack of effective structural cues. Also, it is assumed that all predicted landmarks are semantically relevant despite having no ground truth supervision. In the current work, we introduce a consistency-guided bottleneck in an image reconstruction-based pipeline that leverages landmark consistency – a measure of compatibility score with the pseudo ground truth – to generate adaptive heatmaps. We propose obtaining pseudo-supervision via forming landmark correspondence across images. The consistency then modulates the uncertainty of the discovered landmarks in the generation of adaptive heatmaps which rank consistent landmarks above their noisy counterparts, providing effective structural information for improved robustness. Evaluations on five diverse datasets including MAFL, AFLW, LS3D, Cats, and Shoes demonstrate excellent performance of the proposed approach compared to the existing state-of-the-art methods. Our code is publicly available at https://github.com/MamonaAwan/CGB_ULD.
Model Diagram
Paper Link:
Citation:
@InProceedings{awan2023unsupervised,
title={Unsupervised Landmark Discovery Using Consistency Guided Bottleneck},
author={Mamona Awan and Muhammad Haris Khan and Sanoojan Baliah and
Muhammad Ahmad Waseem and Salman Khan and Fahad Shahbaz Khan and Arif
Mahmood},
booktitle = {Proceedings of the British Machine Vision Conference},
year={2023},
}
Face Pyramid Vision Transformer (BMVC, 2022)
Abstract:
A novel Face Pyramid Vision Transformer (FPVT) is proposed to learn a
discriminative multi-scale facial representations for face recognition and verification. In FPVT,
Face Spatial Reduction Attention (FSRA) and Dimensionality Reduction (FDR) layers are
employed to make the feature maps compact, thus reducing the computations. An Improved
Patch Embedding (IPE) algorithm is proposed to exploit the benefits of CNNs in ViTs (e.g.,
shared weights, local context, and receptive fields) to model lower-level edges to higher-level
semantic primitives. Within FPVT framework, a Convolutional Feed-Forward Network (CFFN) is
proposed that extracts locality information to learn low level facial information. The proposed
FPVT is evaluated on seven benchmark datasets and compared with ten existing state-of-the-
art methods, including CNNs, pure ViTs, and Convolutional ViTs. Despite fewer parameters,
FPVT has demonstrated excellent performance over the compared methods. Project page is
available at https://khawar-islam.github.io/fpvt/.
Model Diagram
Paper Link:
Citation:
@InProceedings{Khawar_BMVC22_FPVT,
author = {Khawar Islam, Muhammad Zaigham Zaheer, Arif Mahmood},
title = {Face Pyramid Vision Transformer},
booktitle = {Proceedings of the British Machine Vision Conference},
year = {2022}
}
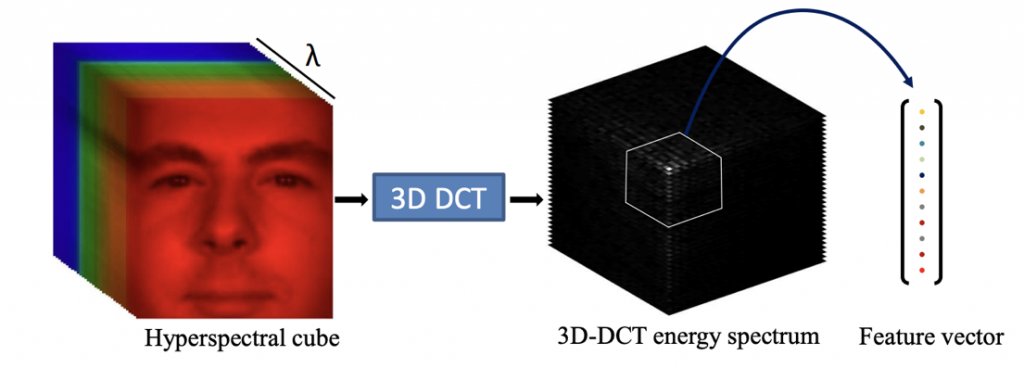
Hyperspectral Face Recognition using 3D-DCT and Partial Least Squares (BMVC, 2013)
Abstract:
Model Diagram
Paper Link:
Citation:
@inproceedings{,
title={Hyperspectral Face Recognition using 3D-DCT and Partial Least Squares },
author={Muhammad Uzair, Arif Mahmood, Ajmal Mian },
year = {2013},
booktitle = {Proceedings of the British Machine Vision Conference},
publisher = {BMVA Press}}
Hierarchical Sparse Spectral Clustering for Image Set Classification (BMVC, 2012)
Abstract:
Model Diagram
Paper Link:
Citation:
@inproceedings{mahmood2012hierarchical,
title={Hierarchical Sparse Spectral Clustering For Image Set Classification.},
author={Mahmood, Arif and Mian, Ajmal S},
booktitle={Proceedings of the British Machine Vision Conference},
pages={1–11},
year={2012}}
IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)
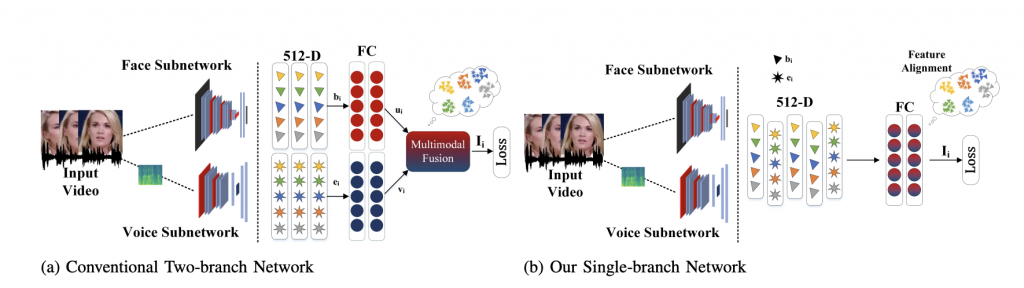
Single-branch Network for Multimodal Training (ICASSP, 2023)
Abstract:
With the rapid growth of social media platforms, users are sharing billions of multimedia posts containing audio, images, and text. Researchers have focused on building autonomous systems capable of processing such multimedia data to solve challenging multimodal tasks including cross-modal retrieval, matching, and verification. Existing works use separate networks to extract embeddings of each modality to bridge the gap between them. The modular structure of their branched networks is fundamental in creating numerous multimodal applications and has become a defacto standard to handle multiple modalities. In contrast, we propose a novel single-branch network capable of learning discriminative representation of unimodal as well as multimodal tasks without changing the network. An important feature of our single-branch network is that it can be trained either using single or multiple modalities without sacrificing performance. We evaluated our proposed singlebranch network on the challenging multimodal problem (facevoice association) for cross-modal verification and matching tasks with various loss formulations. Experimental results demonstrate the superiority of our proposed single-branch network over the existing methods in a wide range of experiments. Code: https://github.com/msaadsaeed/SBNet
Model Diagram
Paper Link:
Citation:
@INPROCEEDINGS{10097207,
author={Saeed, Muhammad Saad and Nawaz, Shah and Khan, Muhammad Haris and Zaigham Zaheer, Muhammad and Nandakumar, Karthik and Yousaf, Muhammad Haroon and Mahmood, Arif},
booktitle={IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)},
title={Single-branch Network for Multimodal Training},
year={2023},
pages={1-5},
doi={10.1109/ICASSP49357.2023.10097207}}
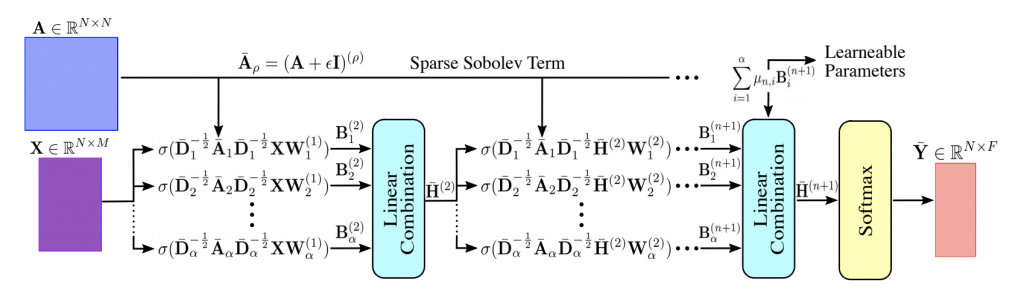
Higher-Order Sparse Convolutions In Graph Neural Networks (ICASSP, 2023)
Abstract:
Model Diagram
Paper Link:
Citation:
@INPROCEEDINGS{10096494,
author={Giraldo, Jhony H. and Javed, Sajid and Mahmood, Arif and Malliaros, Fragkiskos D. and Bouwmans, Thierry},
booktitle={ICASSP 2023 – 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)},
title={Higher-Order Sparse Convolutions in Graph Neural Networks},
year={2023},
pages={1-5},
doi={10.1109/ICASSP49357.2023.10096494}}
IEEE International Conference on Image Processing (ICIP)
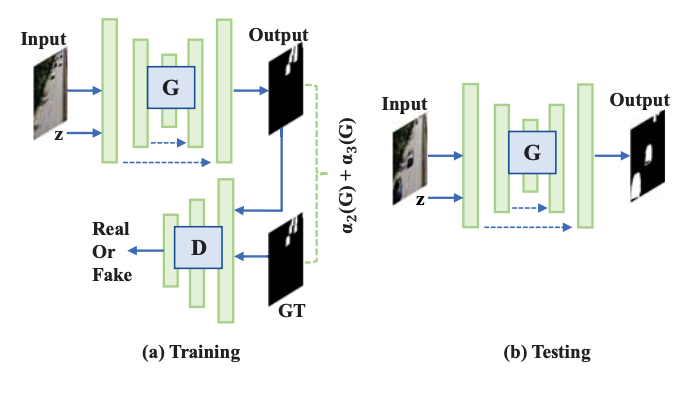
Dynamic Background Subtraction using Least Squares Adversarial Learning (IEEE ICIP, 2020)
Abstract:
Model Diagram
Paper Link:
Citation:
@INPROCEEDINGS{9191235,
author={Sultana, Maryam and Mahmood, Arif and Bouwmans, Thierry and Jung, Soon Ki},
booktitle={2020 IEEE International Conference on Image Processing (ICIP)},
title={Dynamic Background Subtraction Using Least Square Adversarial Learning},
year={2020},
pages={3204-3208},
doi={10.1109/ICIP40778.2020.9191235}}
CS-RPCA: Clustered Sparse RPCA for Moving Object Detection (ICIP, 2020)
Abstract:
Moving object detection (MOD) is an important step for many computer vision applications. In the last decade, it is evident that RPCA has shown to be a potential solution for MOD and achieved a promising performance under various challenging background scenes. However, because of the lack of different types of features, RPCA still shows degraded performance in many complicated background scenes such as dynamic backgrounds, cluttered foreground objects, and camouflage. To address these problems, this paper presents a Clustered Sparse RPCA (CS-RPCA) for MOD under challenging environments. The proposed algorithm extracts multiple features from video sequences and then employs RPCA to get the low-rank and sparse component from each representation. The sparse subspaces are then emerged into a common sparse component using Grassmann manifold. We proposed a novel objective function which computes the composite sparse component from multiple representations and it is solved using non-negative matrix factorization method. The proposed algorithm is evaluated on two challenging datasets for MOD. Results demonstrate excellent performance of the proposed algorithm as compared to existing state-of-the-art methods.
Paper Link:
Citation:
@INPROCEEDINGS{9190734,
author={Javed, Sajid and Mahmood, Arif and Dias, Jorge and Werghi, Naoufel},
booktitle={2020 IEEE International Conference on Image Processing (ICIP)},
title={CS-RPCA: Clustered Sparse RPCA for Moving Object Detection},
year={2020},
pages={3209-3213},
doi={10.1109/ICIP40778.2020.9190734}}
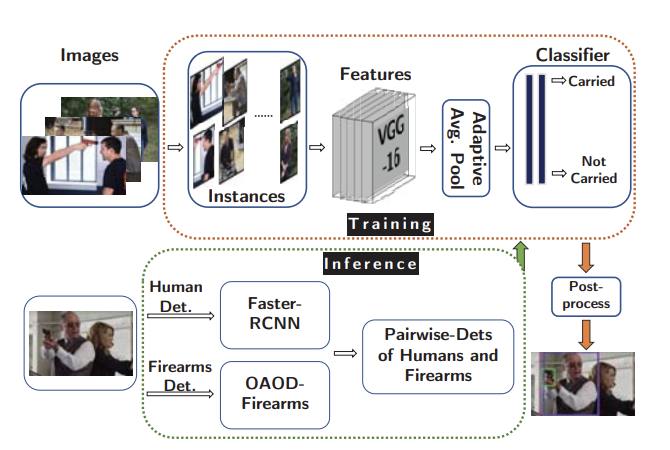
Localizing firearm carriers by identifying human-object pairs ( ICIP, 2020)
Abstract:
Model Diagram
Paper Link:
Citation:
@INPROCEEDINGS{9190886,
author={Basit, Abdul and Munir, Muhammad Akhtar and Ali, Mohsen and Werghi, Naoufel and Mahmood, Arif},
booktitle={2020 IEEE International Conference on Image Processing (ICIP)},
title={Localizing Firearm Carriers By Identifying Human-Object Pairs},
year={2020},
pages={2031-2035}}
IEEE International Geoscience and Remote Sensing Symposium (IGRSS)
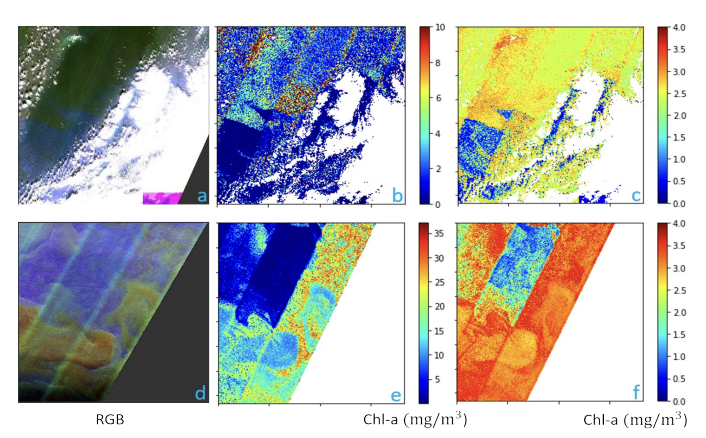
Ocean Color Net (OCN) for the Barents Sea (IEEE IGRSS, 2020)
Abstract:
Model Diagram
Paper Link:
Citation:
@INPROCEEDINGS{9323687,
author={Asim, Muhammad and Brekke, Camilla and Mahmood, Arif and Eltoft, Torbjørn and Reigstad, Marit},
booktitle={IGARSS 2020 – 2020 IEEE International Geoscience and Remote Sensing Symposium},
title={Ocean Color Net (OCN) for the Barents Sea},
year={2020},
pages={5881-5884},
doi={10.1109/IGARSS39084.2020.9323687}}
IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS)
Structural Low-Rank Tracking (AVSS, 2019)
Abstract:
Model Diagram
Paper Link:
Citation:
@INPROCEEDINGS{8909852,
author={Javed, Sajid and Mahmood, Arif and Dias, Jorge and Werghi, Naoufel},
booktitle={2019 16th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS)},
title={Structural Low-Rank Tracking},
year={2019},
pages={1-8},
doi={10.1109/AVSS.2019.8909852}}
IEEE Transactions on Image Processing (TIP)
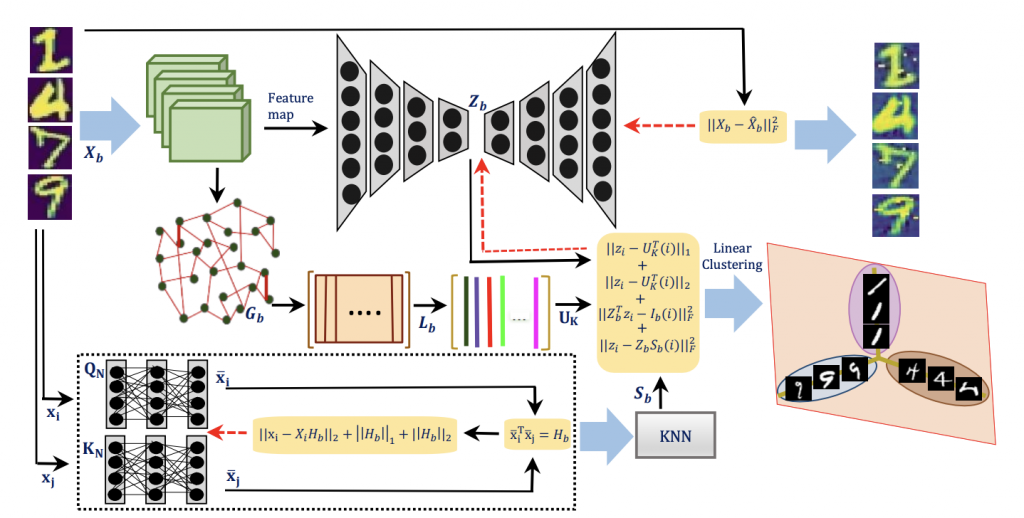
Learning Structure Aware Deep Spectral Embedding (TIP, 2023)
Abstract:
Model Diagram
Paper Link:
Citation:
@ARTICLE{10179276,
author={Yaseen, Hira and Mahmood, Arif},
journal={IEEE Transactions on Image Processing},
title={Learning Structure Aware Deep Spectral Embedding},
year={2023},
volume={32},
number={},
pages={3939-3948},
doi={10.1109/TIP.2023.3282074}}
Multiplex Cellular Communities in Multi-Gigapixel Colorectal Cancer Histology Images for Tissue Phenotyping (TIP, 2020)
Abstract:
Model Diagram
Paper Link:
Citation:
@article{javed2020multiplex,
title={Multiplex cellular communities in multi-gigapixel colorectal cancer histology images for tissue phenotyping},
author={Javed, Sajid and Mahmood, Arif and Werghi, Naoufel and Benes, Ksenija and Rajpoot, Nasir},
journal={IEEE Transactions on Image Processing},
volume={29},
pages={9204–9219},
year={2020},
publisher={IEEE}
}
Robust Structural Low-Rank Tracking (TIP, 2020)
Abstract:
Model Diagram
Paper Link:
Citation:
@article{javed2020robust,
title={Robust structural low-rank tracking},
author={Javed, Sajid and Mahmood, Arif and Dias, Jorge and Werghi, Naoufel},
journal={IEEE Transactions on Image Processing},
volume={29},
pages={4390–4405},
year={2020},
publisher={IEEE}}
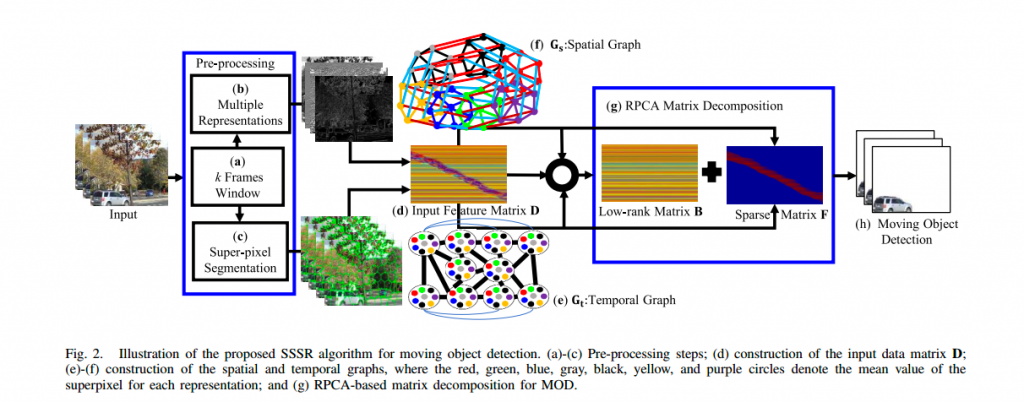
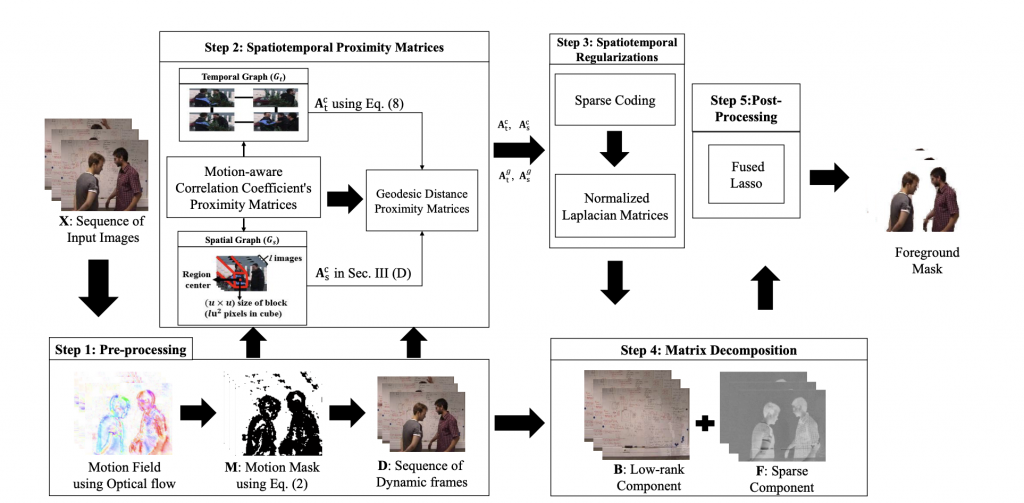
Moving Object Detection in Complex Scene Using Spatiotemporal Structured-Sparse RPCA (TIP, 2019)
Abstract:
Model Diagram
Paper Link:
Citation:
@article{javed2018moving,
title={Moving object detection in complex scene using spatiotemporal structured-sparse RPCA},
author={Javed, Sajid and Mahmood, Arif and Al-Maadeed, Somaya and Bouwmans, Thierry and Jung, Soon Ki},
journal={IEEE Transactions on Image Processing},
volume={28},
number={2},
pages={1007–1022},
year={2018},
publisher={IEEE}}
Background–Foreground Modeling Based on Spatiotemporal Sparse Subspace Clustering (TIP, 2017)
Abstract:
Model Diagram
Paper Link:
Citation:
@article{javed2017background,
title={Background–foreground modeling based on spatiotemporal sparse subspace clustering},
author={Javed, Sajid and Mahmood, Arif and Bouwmans, Thierry and Jung, Soon Ki},
journal={IEEE Transactions on Image Processing},
volume={26},
number={12},
pages={5840–5854},
year={2017},
publisher={IEEE}}
Constrained Metric Learning by Permutation Inducing Isometries (TIP, 2016)
Abstract:
Model Diagram

Paper Link:
Citation:
@article{bosveld2015constrained,
title={Constrained metric learning by permutation inducing isometries},
author={Bosveld, Joel and Mahmood, Arif and Huynh, Du Q and Noakes, Lyle},
journal={IEEE Transactions on Image Processing},
volume={25},
number={1},
pages={92–103},
year={2015},
publisher={IEEE}
}
Hyperspectral Face Recognition With Spatio Spectral Information Fusion and PLS Regression (TIP, 2015)
Abstract:
Model Diagram
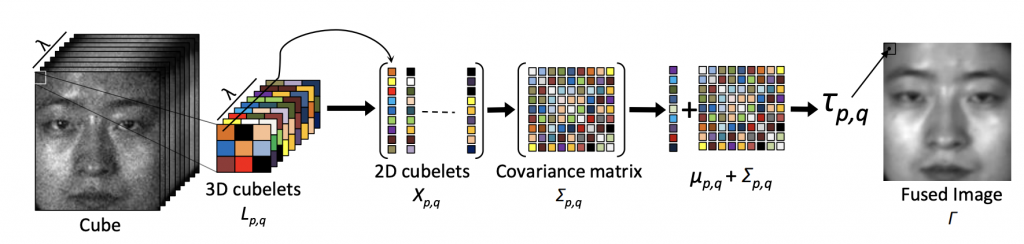
Paper Link:
Citation:
@ARTICLE{7010906,
author={Uzair, Muhammad and Mahmood, Arif and Mian, Ajmal},
journal={IEEE Transactions on Image Processing},
title={Hyperspectral Face Recognition With Spatiospectral Information Fusion and PLS Regression},
year={2015},
volume={24},
number={3},
pages={1127-1137},
doi={10.1109/TIP.2015.2393057}}
Correlation-Coefficient-Based Fast Template Matching Through Partial Elimination (TIP, 2012)
Abstract:
Paper Link:
Citation:
@ARTICLE{6044713,
author={Mahmood, Arif and Khan, Sohaib},
journal={IEEE Transactions on Image Processing},
title={Correlation-Coefficient-Based Fast Template Matching Through Partial Elimination},
year={2012},
volume={21},
number={4},
pages={2099-2108},
doi={10.1109/TIP.2011.2171696}}
Exploiting Transitivity of Correlation for Fast Template Matching (TIP, 2010)
Abstract:
Paper Link:
Citation:
@ARTICLE{5439796,
author={Mahmood, Arif and Khan, Sohaib},
journal={IEEE Transactions on Image Processing},
title={Exploiting Transitivity of Correlation for Fast Template Matching},
year={2010},
volume={19},
number={8},
pages={2190-2200},
doi={10.1109/TIP.2010.2046809}}
IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI)
Histogram of Oriented Principal Components for Cross-View Action Recognition (TPAMI, 2016)
Abstract:
Model Diagram
Paper Link:
Citation:
@article{rahmani2016histogram,
title={Histogram of oriented principal components for cross-view action recognition},
author={Rahmani, Hossein and Mahmood, Arif and Huynh, Du and Mian, Ajmal},
journal={IEEE transactions on pattern analysis and machine intelligence},
volume={38},
number={12},
pages={2430–2443},
year={2016},
publisher={IEEE}}
IEEE Transactions on Neural Networks and Learning Systems (TNNLS)
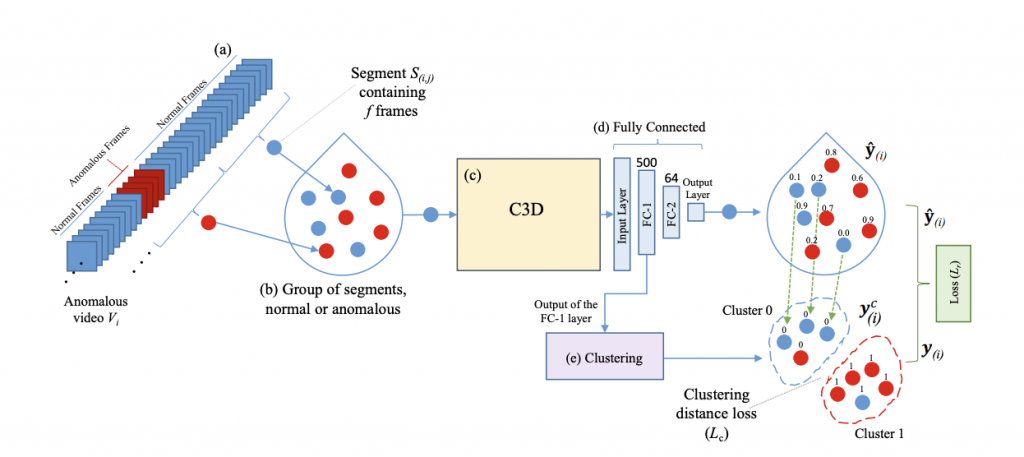
Clustering aided weakly supervised training to detect anomalous events in surveillance videos (TNNLS, 2023)
Abstract:
Model Diagram
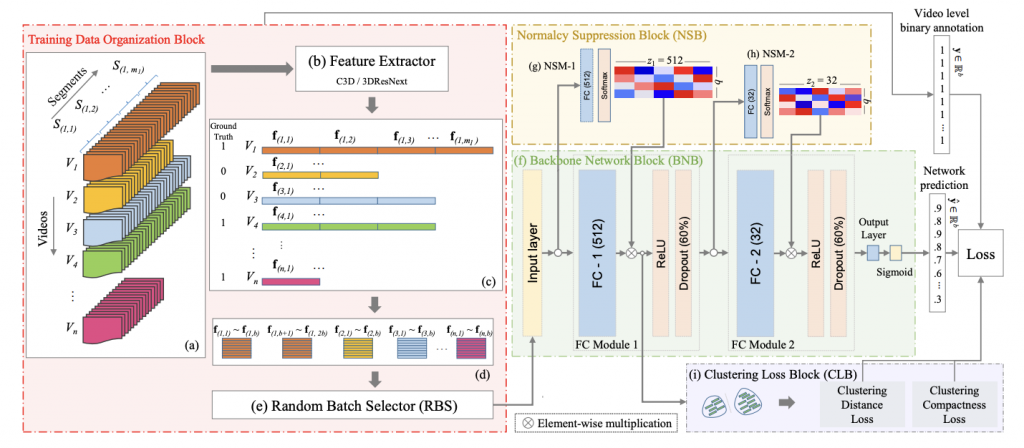
Paper Link:
Citation:
@ARTICLE{10136845,
author={Zaheer, Muhammad Zaigham and Mahmood, Arif and Astrid, Marcella and Lee, Seung-Ik},
journal={IEEE Transactions on Neural Networks and Learning Systems},
title={Clustering Aided Weakly Supervised Training to Detect Anomalous Events in Surveillance Videos},
year={2023},
pages={1-14}}
IEEE Transactions on Cybernetics (TC)
Hierarchical Spatiotemporal Graph Regularized Discriminative Correlation Filter for Visual Object Tracking (TC, 2021)
Abstract:
Model Diagram
Paper Link:
Citation:
@ARTICLE{9475879,
author={Javed, Sajid and Mahmood, Arif and Dias, Jorge and Seneviratne, Lakmal and Werghi, Naoufel},
journal={IEEE Transactions on Cybernetics},
title={Hierarchical Spatiotemporal Graph Regularized Discriminative Correlation Filter for Visual Object Tracking},
year={2022},
volume={52},
number={11},
pages={12259-12274},
doi={10.1109/TCYB.2021.3086194}}
IEEE Transactions on Multimedia (TMM)
Quantification of Occlusion Handling Capability of a 3D Human Pose Estimation Framework (TMM, 2022)
Abstract:
Model Diagram
Paper Link:
Citation:
@article{ghafoor2022quantification,
title={Quantification of occlusion handling capability of 3D human pose estimation framework},
author={Ghafoor, Mehwish and Mahmood, Arif},
journal={IEEE Transactions on Multimedia},
year={2022},
publisher={IEEE}}
Unsupervised Moving Object Detection in Complex Scenes Using Adversarial Regularizations (TMM, 2020)
Abstract:
Model Diagram
Paper Link:
Citation:
@article{sultana2020unsupervised,
title={Unsupervised moving object detection in complex scenes using adversarial regularizations},
author={Sultana, Maryam and Mahmood, Arif and Jung, Soon Ki},
journal={IEEE Transactions on Multimedia},
volume={23},
pages={2005–2018},
year={2020},
publisher={IEEE}
}
IEEE Transactions on Circuits and Systems for Video Technology (CSVT)
Spatiotemporal Low-Rank Modeling for Complex Scene Background Initialization (CSVT, 2018)
Abstract:
Model Diagram
Paper Link:
Citation:
@article{javed2016spatiotemporal,
title={Spatiotemporal low-rank modeling for complex scene background initialization},
author={Javed, Sajid and Mahmood, Arif and Bouwmans, Thierry and Jung, Soon Ki},
journal={IEEE Transactions on Circuits and Systems for Video Technology},
volume={28},
number={6},
pages={1315–1329},
year={2016},
publisher={IEEE}
}
IEEE Transactions on Signal and Information Processing over Networks (TSIPN)
Reconstruction of Time-Varying Graph Signals via Sobolev Smoothness (TSIPN, 2022)
Abstract:
Model Diagram
Paper Link:
Citation:
@article{giraldo2022reconstruction,
title={Reconstruction of time-varying graph signals via Sobolev smoothness},
author={Giraldo, Jhony H and Mahmood, Arif and Garcia-Garcia, Belmar and Thanou, Dorina and Bouwmans, Thierry},
journal={IEEE Transactions on Signal and Information Processing over Networks},
volume={8},
pages={201–214},
year={2022},
publisher={IEEE}
}
IEEE Transactions on Knowledge and Data Engineering (TKDE)
Using Geodesic Space Density Gradients for Network Community Detection (TKDE, 2017)
Abstract:
Model Diagram
Citation:
@article{mahmood2017using,
title={Using geodesic space density gradients for network community detection},
author={Mahmood, Arif and Small, Michael and Al-Maadeed, Somaya Ali and Rajpoot, Nasir},
journal={IEEE Transactions on Knowledge and Data Engineering (TKDE)},
volume={29},
number={4},
pages={921–935},
year={2017},
publisher={IEEE}}
Subspace Based Network Community Detection Using Sparse Linear Coding (TKDE, 2016)
Abstract:
Model Diagram
Citation:
@article{mahmood2016subspace,
title={Subspace Based Network Community Detection Using Sparse Linear Coding},
author={Mahmood, Arif and Small, Michael},
journal={IEEE Transactions on Knowledge and Data Engineering (TKDE)},
volume={28},
number={3},
pages={801–812},
year={2016},
publisher={IEEE}}
IEEE Transactions on Computational Social Systems (TCSS)
Detection and Localization of Firearm Carriers in Complex Scenes for Improved Safety Measures (TCSS, 2023)
Abstract:
Model Diagram

Paper Link:
Citation:
@ARTICLE{10258124,
author={Mahmood, Arif and Basit, Abdul and Munir, Muhammad Akhtar and Ali, Mohsen},
journal={IEEE Transactions on Computational Social Systems},
title={Detection and Localization of Firearm Carriers in Complex Scenes for Improved Safety Measures},
year={2023}, pages={1-11}}
IEEE Transactions on Cloud Computing (TCC)
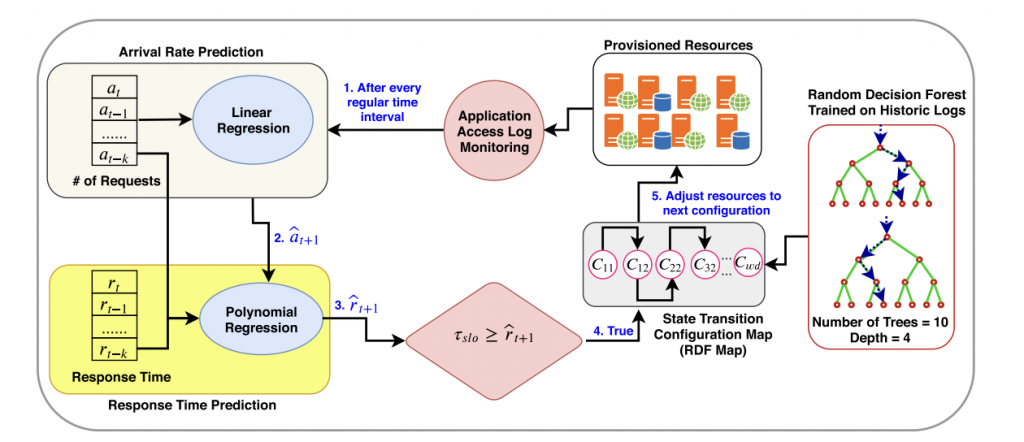
Predictive Auto-scaling of Multi-tier Applications Using Performance Varying Cloud Resources (TCC, 2019)
Abstract:
Model Diagram
Paper Link:
Citation:
@article{iqbal2019predictive,
title={Predictive auto-scaling of multi-tier applications using performance varying cloud resources},
author={Iqbal, Waheed and Erradi, Abdelkarim and Abdullah, Muhammad and Mahmood, Arif},
journal={IEEE Transactions on Cloud Computing},
volume={10},
number={1},
pages={595–607},
year={2019},
publisher={IEEE}
}
IEEE Transactions on Services Computing (TSC)
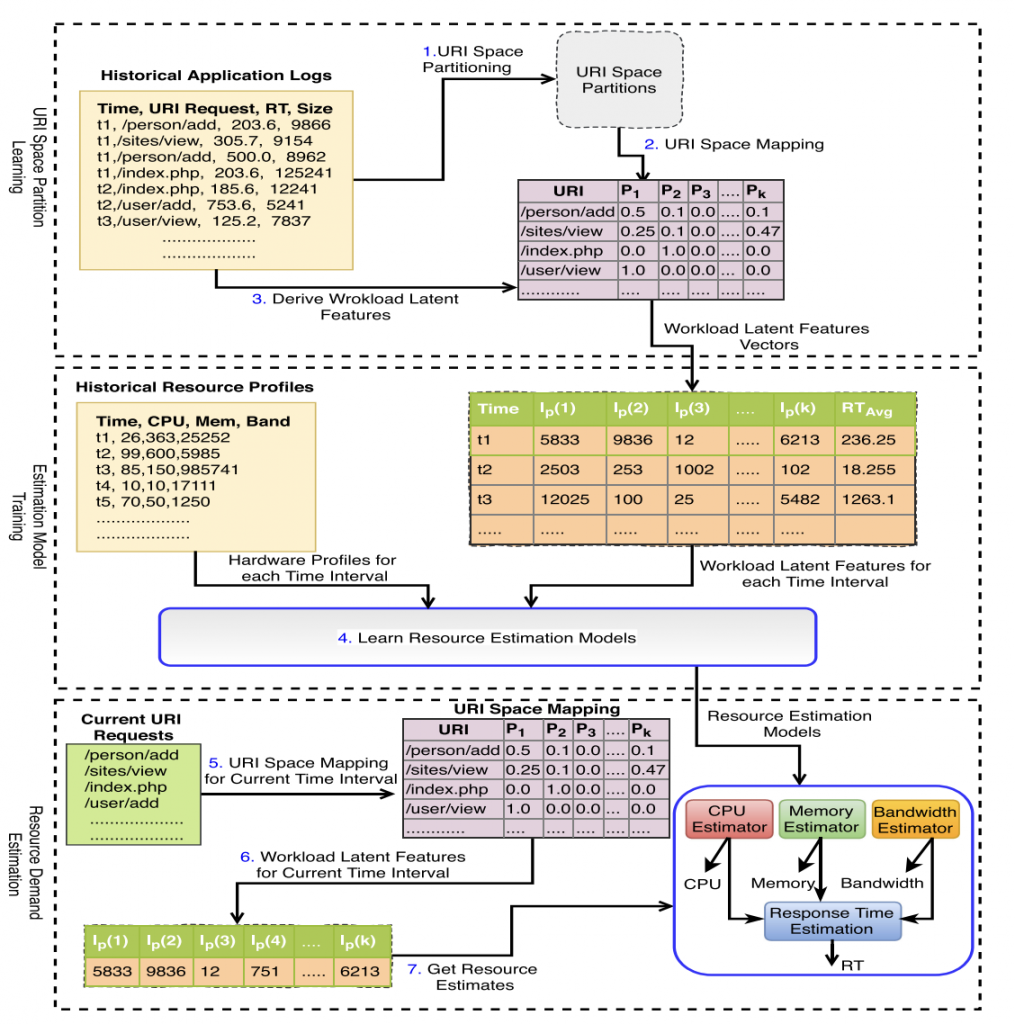
Web application resource requirements estimation based on the workload latent features (TSC, 2019)
Abstract:
Model Diagram
Paper Link:
Citation:
@article{erradi2019web,
title={Web application resource requirements estimation based on the workload latent features},
author={Erradi, Abdelkarim and Iqbal, Waheed and Mahmood, Arif and Bouguettaya, Athman},
journal={IEEE Transactions on Services Computing},
volume={14},
number={6},
pages={1638–1649},
year={2019},
publisher={IEEE}
}
IEEE Journal of Biomedical and Health Informatics (JBHI)
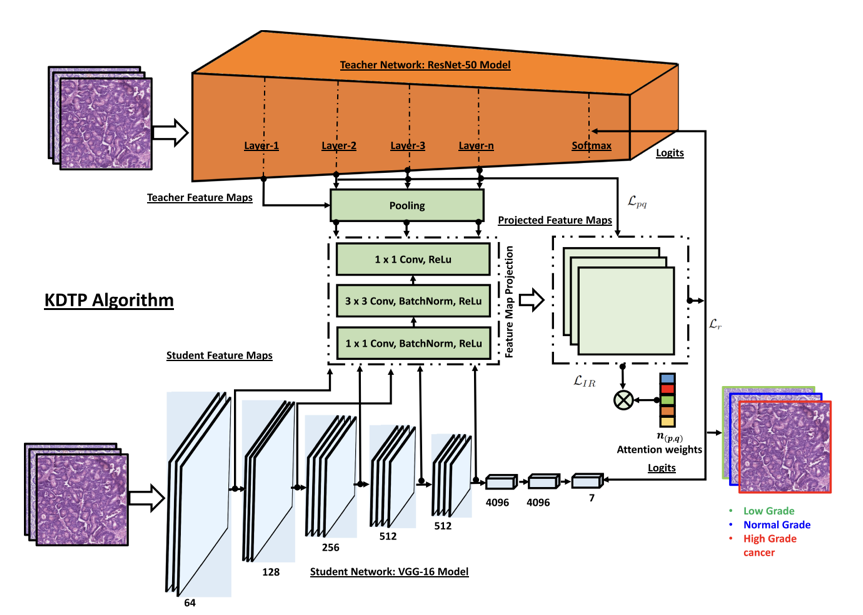
Knowledge Distillation in Histology Landscape by Multi-Layer Features Supervision (JBHI, 2023)
Abstract:
Model Diagram
Paper Link:
Citation:
@ARTICLE{10018566,
author={Javed, Sajid and Mahmood, Arif and Qaiser, Talha and Werghi, Naoufel},
journal={IEEE Journal of Biomedical and Health Informatics},
title={Knowledge Distillation in Histology Landscape by Multi-Layer Features Supervision},
year={2023},
volume={27},
number={4},
pages={2037-2046},
doi={10.1109/JBHI.2023.3237749}}
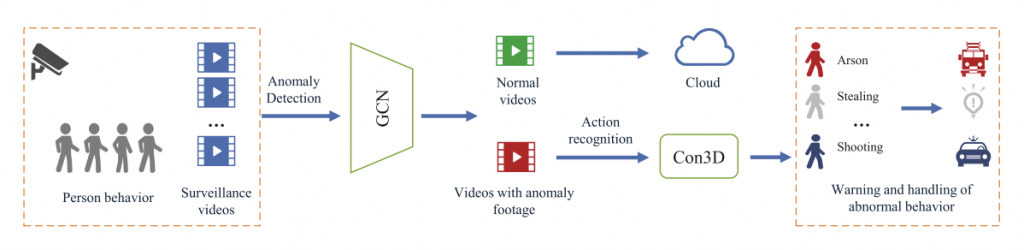
An End-to-End Human Abnormal Behavior Recognition Framework for Crowds with Mentally Disordered Individuals (JBHI, 2022)
Abstract:
Model Diagram
Paper Link:
Citation:
@article{hao2021end,
title={An End-to-End Human Abnormal Behavior Recognition Framework for Crowds With Mentally Disordered Individuals},
author={Hao, Yixue and Tang, Zaiyang and Alzahrani, Bander and Alotaibi, Reem and Alharthi, Reem and Zhao, Miaomiao and Mahmood, Arif},
journal={IEEE Journal of Biomedical and Health Informatics},
volume={26},
number={8},
pages={3618–3625},
year={2021},
publisher={IEEE}
}
IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing (JSTARS)
Improving Chlorophyll-a Estimation from sentinel-2 (MSI) in the Barents Sea using Machine Learning (JSTARS, 2021)
Abstract:
Model Diagram
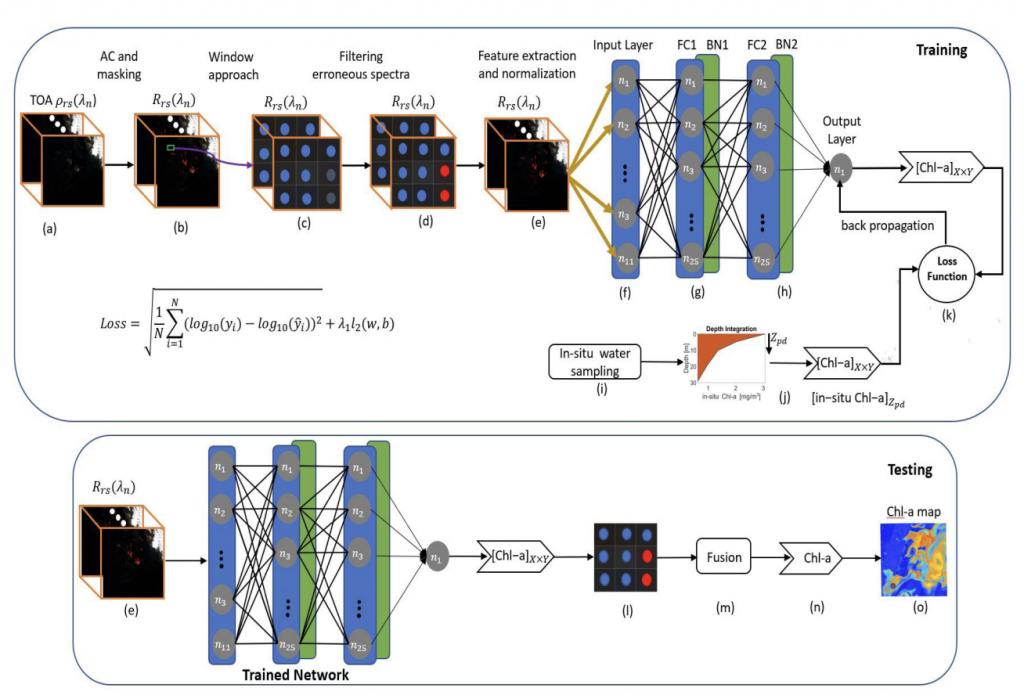
Paper Link:
Citation:
@article{asim2021improving,
title={Improving chlorophyll-a estimation from Sentinel-2 (MSI) in the Barents Sea using machine learning},
author={Asim, Muhammad and Brekke, Camilla and Mahmood, Arif and Eltoft, Torbj{\o}rn and Reigstad, Marit},
journal={IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing},
volume={14},
pages={5529–5549},
year={2021},
publisher={IEEE}}
IEEE Systems Journal
Predictive Autoscaling of Microservices Hosted in Fog Microdata Center (Systems, 2020)
Abstract:
Model Diagram
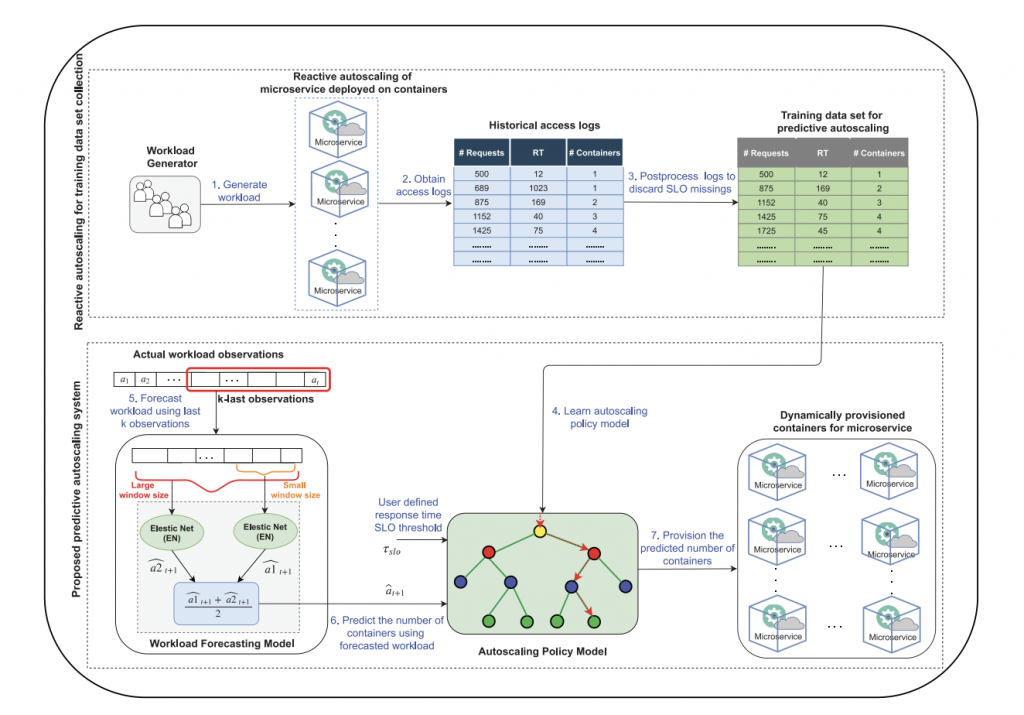
Paper Link:
Citation:
@article{abdullah2020predictive,
title={Predictive autoscaling of microservices hosted in fog microdata center},
author={Abdullah, Muhammad and Iqbal, Waheed and Mahmood, Arif and Bukhari, Faisal and Erradi, Abdelkarim},
journal={IEEE Systems Journal},
volume={15},
number={1},
pages={1275–1286},
year={2020},
publisher={IEEE}
}
IEEE Signal Processing Letters (SPL)
A Self-Reasoning Framework for Anomaly Detection Using Video-Level Labels (SPL, 2020)
Abstract:
Model Diagram
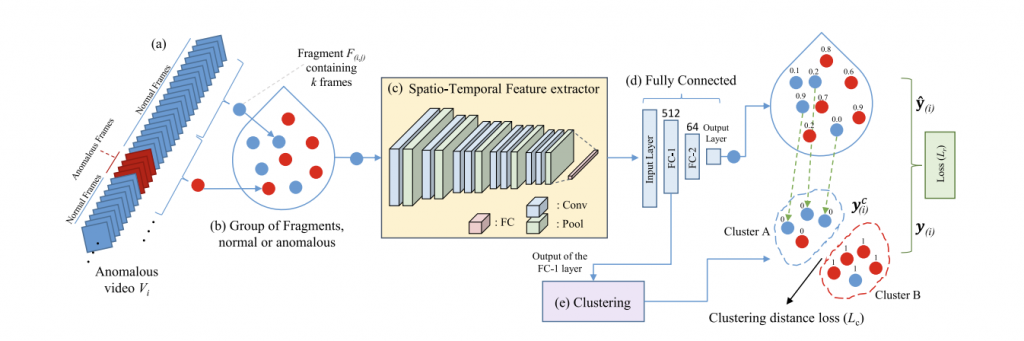
Paper Link:
Citation:
@article{zaheer2020self,
title={A self-reasoning framework for anomaly detection using video-level labels},
author={Zaheer, Muhammad Zaigham and Mahmood, Arif and Shin, Hochul and Lee, Seung-Ik},
journal={IEEE Signal Processing Letters},
volume={27},
pages={1705–1709},
year={2020},
publisher={IEEE}
}
IEEE Access
A Novel Algorithm Based on a Common Subspace Fusion for Visual Object Tracking (Access, 2022)
Abstract:
Model Diagram
Paper Link:
Citation:
@article{javed2022novel,
title={A novel algorithm based on a common subspace fusion for visual object tracking},
author={Javed, Sajid and Mahmood, Arif and Ullah, Ihsan and Bouwmans, Thierry and Khonji, Majid and Dias, Jorge Manuel Miranda and Werghi, Naoufel},
journal={IEEE Access},
volume={10},
pages={24690–24703},
year={2022},
publisher={IEEE}
}
Internal Emotion Classification Using EEG Signal with Sparse Discriminative Ensemble (Access, 2019)
Abstract:
Model Diagram
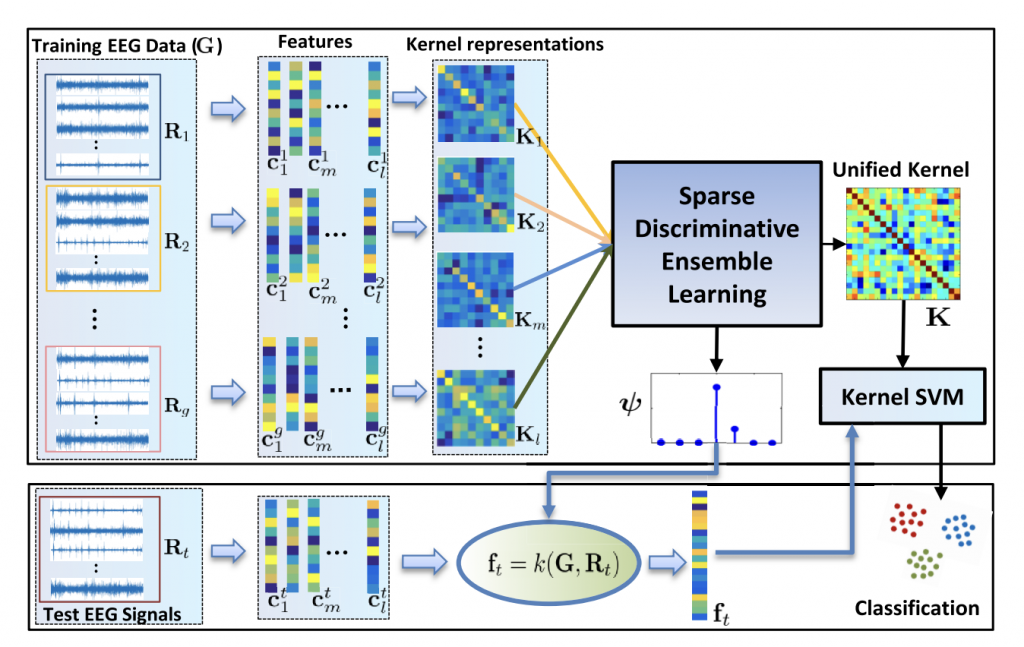
Paper Link:
Citation:
@article{ullah2019internal,
title={Internal emotion classification using EEG signal with sparse discriminative ensemble},
author={Ullah, Habib and Uzair, Muhammad and Mahmood, Arif and Ullah, Mohib and Khan, Sultan Daud and Cheikh, Faouzi Alaya},
journal={IEEE Access},
volume={7},
pages={40144–40153},
year={2019},
publisher={IEEE}
}
Multi-Order Statistical Descriptors for Real-Time Face Recognition and Object Classification (Access, 2018)
Abstract:
Model Diagram
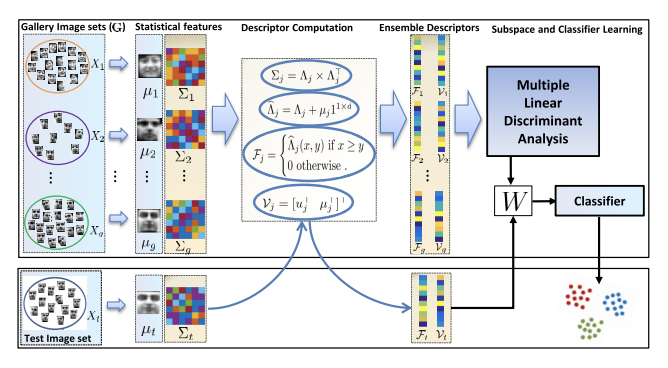
Paper Link:
Citation:
@article{mahmood2018multi,
title={Multi-order statistical descriptors for real-time face recognition and object classification},
author={Mahmood, Arif and Uzair, Muhammad and Al-Maadeed, Somaya},
journal={IEEE Access},
volume={6},
pages={12993–13004},
year={2018},
publisher={IEEE}
}
Palmprint Identification Using an Ensemble of Sparse Representations (Access, 2018)
Abstract:
Paper Link:
Citation:
@article{rida2018palmprint,
title={Palmprint identification using an ensemble of sparse representations},
author={Rida, Imad and Al-Maadeed, Somaya and Mahmood, Arif and Bouridane, Ahmed and Bakshi, Sambit},
journal={IEEE Access},
volume={6},
pages={3241–3248},
year={2018},
publisher={IEEE}}
Nucleus classification in histology images using message passing network (MEDIA, 2022)
Abstract:
Paper Link:
Citation:
@article{hassan2022nucleus,
title={Nucleus classification in histology images using message passing network},
author={Hassan, Taimur and Javed, Sajid and Mahmood, Arif and Qaiser, Talha and Werghi, Naoufel and Rajpoot, Nasir},
journal={Medical Image Analysis},
volume={79},
pages={102480},
year={2022},
publisher={Elsevier}
}
Spatially Constrained Context-Aware Hierarchical Deep Correlation Filters for Nucleus Detection in Histology Images (MEDIA, 2021)
Abstract:
Paper Link:
Citation:
@article{javed2021spatially,
title={Spatially constrained context-aware hierarchical deep correlation filters for nucleus detection in histology images},
author={Javed, Sajid and Mahmood, Arif and Dias, Jorge and Werghi, Naoufel and Rajpoot, Nasir},
journal={Medical Image Analysis},
volume={72},
pages={102104},
year={2021},
publisher={Elsevier}
}
Cellular Community Detection For Tissue Phenotyping In Colorectal Cancer Histology Images (MEDIA, 2020)
Abstract:
Model Diagram
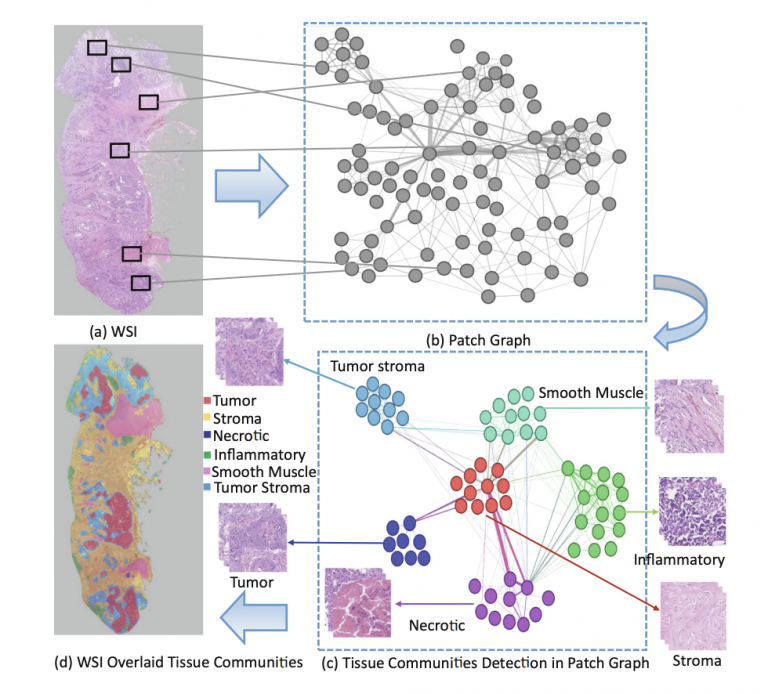
Paper Link:
Citation:
@article{javed2020cellular,
title={Cellular Community Detection For Tissue Phenotyping In Colorectal Cancer Histology Images},
author={Javed, Sajid and Mahmood, Arif and Fraz, Muhammad Moazam and Koohbanania, Navid Alemi and Benesc, Ksenija and Tsangc, Yee-Wah and Hewittc, Katherine and Epsteind, David and Sneadc, David and Rajpoot, Nasir},
journal={Medical Image Analysis (MEDIA)},
year={2020}}
Multi-focus Image Fusion Using Content Adaptive Blurring (IF, 2019)
Abstract:
Model Diagram

Paper Link:
Citation:
@article{farid2019multi,
title={Multi-focus image fusion using content adaptive blurring},
author={Farid, Muhammad Shahid and Mahmood, Arif and Al-Maadeed, Somaya Ali},
journal={Information fusion},
volume={45},
pages={96–112},
year={2019},
publisher={Elsevier}
}
An Information Fusion Framework for Person Localization Via Body Pose in Spectator Crowds (IF, 2019)
Abstract:
Model Diagram
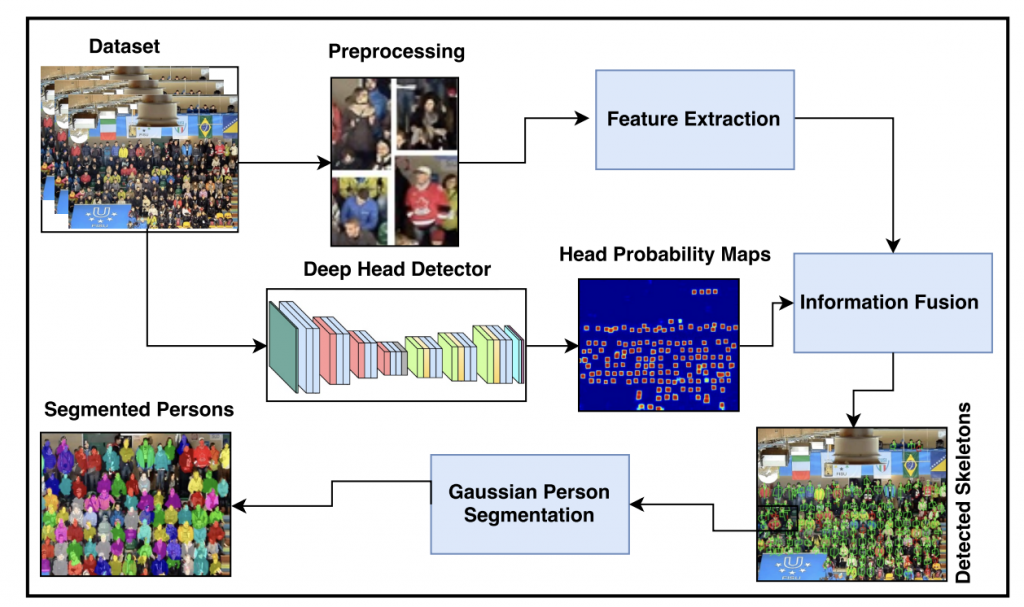
Paper Link:
Citation:
@article{shaban2019information,
title={An information fusion framework for person localization via body pose in spectator crowds},
author={Shaban, Muhammad and Mahmood, Arif and Al-Maadeed, Somaya Ali and Rajpoot, Nasir},
journal={Information Fusion},
volume={51},
pages={178–188},
year={2019},
publisher={Elsevier}
}
Unsupervised Moving Object Segmentation Using Background Subtraction and Optimal Adversarial Noise Sample Search (PR, 2022)
Abstract:
Model Diagram

Paper Link:
Citation:
@article{sultana2022unsupervised,
title={Unsupervised moving object segmentation using background subtraction and optimal adversarial noise sample search},
author={Sultana, Maryam and Mahmood, Arif and Jung, Soon Ki},
journal={Pattern Recognition},
volume={129},
pages={108719},
year={2022},
publisher={Elsevier}
}
Multi-Scale Attention Guided Network for End-to-End Face Alignment and Recognition (JVCIR, 2022)
Abstract:
Paper Link:
Citation:
@article{shakeel2022multi,
title={Multi-scale attention guided network for end-to-end face alignment and recognition},
author={Shakeel, M Saad and Zhang, Yuxuan and Wang, Xin and Kang, Wenxiong and Mahmood, Arif},
journal={Journal of Visual Communication and Image Representation},
volume={88},
pages={103628},
year={2022},
publisher={Elsevier}}
Multi-Level Feature Fusion for Nucleus Detection in Histology Images Using Correlation Filters (CBM, 2022)
Abstract:
Paper Link:
Citation:
@article{javed2022multi,
title={Multi-level feature fusion for nucleus detection in histology images using correlation filters},
author={Javed, Sajid and Mahmood, Arif and Dias, Jorge and Werghi, Naoufel},
journal={Computers in Biology and Medicine},
volume={143},
pages={105281},
year={2022},
publisher={Elsevier}
}
Learning to Localize Image Forgery Using End-to-End Attention Network (NC, 2022)
Abstract:
Paper Link:
Citation:
@article{ganapathi2022learning,
title={Learning to localize image forgery using end-to-end attention network},
author={Ganapathi, Iyyakutti Iyappan and Javed, Sajid and Ali, Syed Sadaf and Mahmood, Arif and Vu, Ngoc-Son and Werghi, Naoufel},
journal={Neurocomputing},
volume={512},
pages={25–39},
year={2022},
publisher={Elsevier}
}
Moving Objects Segmentation Using Generative Adversarial Modeling (NC, 2022)
Abstract:
Paper Link:
Citation:
@article{sultana2022moving,
title={Moving objects segmentation using generative adversarial modeling},
author={Sultana, Maryam and Mahmood, Arif and Bouwmans, Thierry and Khan, Muhammad Haris and Jung, Soon Ki},
journal={Neurocomputing},
volume={506},
pages={240–251},
year={2022},
publisher={Elsevier}
}
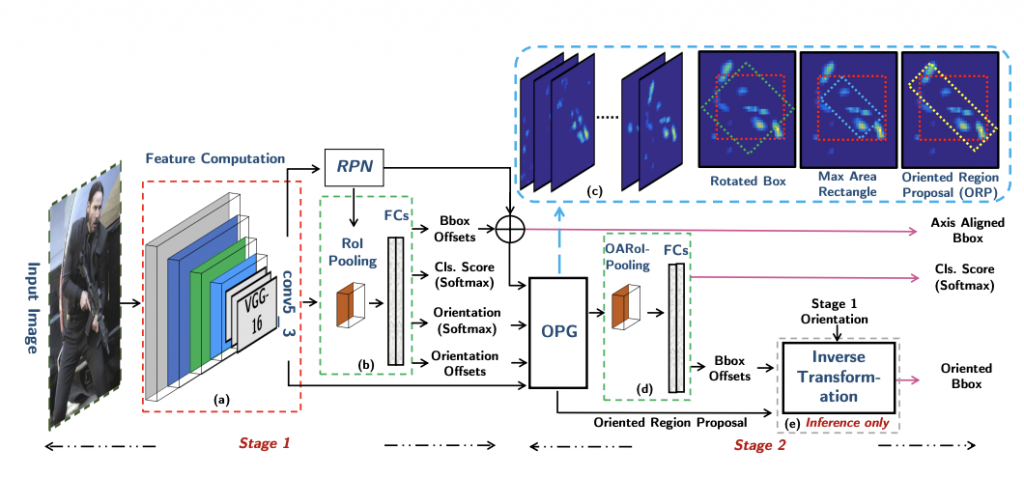
Leveraging orientation for weakly supervised object detection with application to firearm localization (NC, 2021)
Abstract:
Model Diagram
Paper Link:
Citation:
@article{iqbal2021leveraging,
title={Leveraging orientation for weakly supervised object detection with application to firearm localization},
author={Iqbal, Javed and Munir, Muhammad Akhtar and Mahmood, Arif and Ali, Afsheen Rafaqat and Ali, Mohsen},
journal={Neurocomputing},
volume={440},
pages={310–320},
year={2021}}
Dynamic workload patterns prediction for proactive auto-scaling of web applications (JNCA, 2018)
Abstract:
Model Diagram:
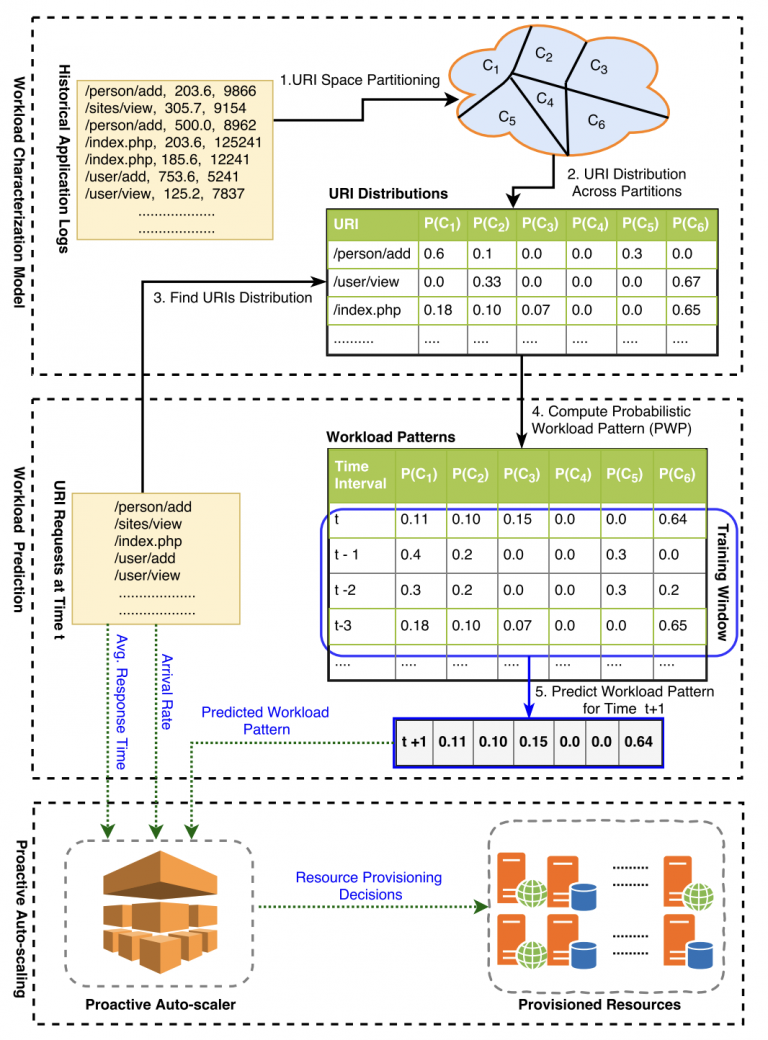
Paper Link:
Citation:
@article{iqbal2018dynamic,
title={Dynamic workload patterns prediction for proactive auto-scaling of web applications},
author={Iqbal, Waheed and Erradi, Abdelkarim and Mahmood, Arif},
journal={Journal of Network and Computer Applications},
volume={124},
pages={94–107},
year={2018},
publisher={Elsevier}}
Masked Linear Regression for Learning Local Receptive Fields for Facial Expression Synthesis (IJCV, 2019)
Abstract:
Paper Link:
Citation:
@article{khan2020masked,
title={Masked linear regression for learning local receptive fields for facial expression synthesis},
author={Khan, Nazar and Akram, Arbish and Mahmood, Arif and Ashraf, Sania and Murtaza, Kashif},
journal={International Journal of Computer Vision},
volume={128},
number={5},
pages={1433–1454},
year={2020},
publisher={Springer}
}
Fake Visual Content Detection Using Two-Stream Convolutional Neural Networks (NCA, 2022)
Abstract:
Model Diagram
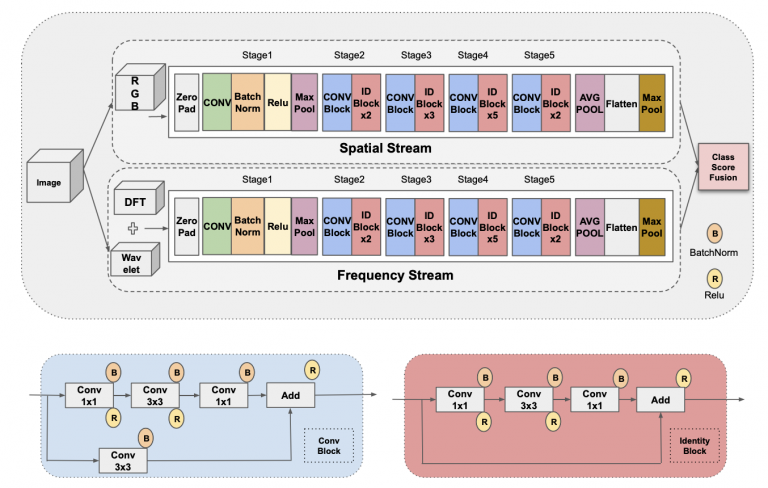
Paper Link:
Citation:
@article{yousaf2022fake,
title={Fake visual content detection using two-stream convolutional neural networks},
author={Yousaf, Bilal and Usama, Muhammad and Sultani, Waqas and Mahmood, Arif and Qadir, Junaid},
journal={Neural Computing and Applications},
volume={34},
number={10},
pages={7991–8004},
year={2022},
publisher={Springer}}
Statistically correlated multi-task learning for autonomous driving (NCA, 2021)
Abstract:
Autonomous driving research is an emerging area in the machine learning domain. Most existing methods perform single-task learning, while multi-task learning (MTL) is more efficient due to the leverage of shared information between different tasks. However, MTL is challenging because different tasks may have different significance and varying ranges. In this work, we propose an end-to-end deep learning architecture for statistically correlated MTL using a single input image. Statistical correlation of the tasks is handled by including shared layers in the architecture. Later network separates into different branches to handle the difference in the behavior of each task. Training a multi-task model with varying ranges may converge the objective function only with larger values. To this end, we explore different normalization schemes and empirically observe that the inverse validation-loss weighted scheme has best performed. In addition to estimating steering angle, braking, and acceleration, we also estimate the number of lanes on the left and the right side of the vehicle. To the best of our knowledge, we are the first to propose an end-to-end deep learning architecture to estimate this type of lane information. The proposed approach is evaluated on four publicly available datasets including Comma.ai, Udacity, Berkeley Deep Drive, and Sully Chen. We also propose a synthetic dataset GTA-V for autonomous driving research. Our experiments demonstrate the superior performance of the proposed approach compared to the current state-of-the-art methods. The GTA-V dataset and the lane annotations on the four existing datasets will be made publicly available via https://cvlab.lums.edu.pk/scmtl/.
Model Diagram
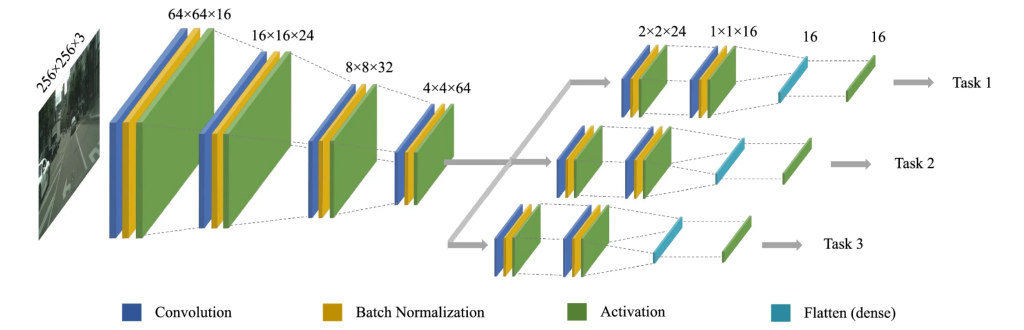
Paper Link:
Citation:
@article{abbas2021statistically,
title={Statistically correlated multi-task learning for autonomous driving},
author={Abbas, Waseem and Khan, M Fakhir and Taj, Murtaza and Mahmood, Arif},
journal={Neural Computing and Applications},
volume={33},
pages={12921–12938},
year={2021}}
Human face super-resolution on poor quality surveillance video footage (NCA, 2021)
Abstract:
Model Diagram
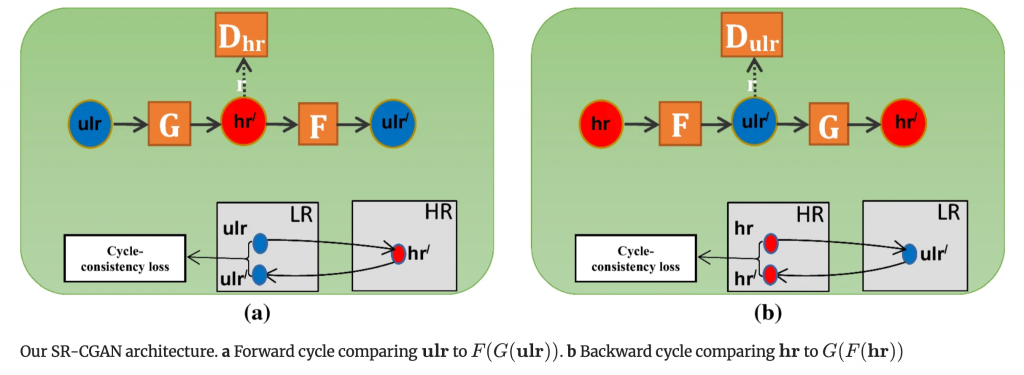
Paper Link:
Citation:
@article{farooq2021human,
title={Human face super-resolution on poor quality surveillance video footage},
author={Farooq, Muhammad and Dailey, Matthew N and Mahmood, Arif and Moonrinta, Jednipat and Ekpanyapong, Mongkol},
journal={Neural Computing and Applications},
volume={33},
pages={13505–13523},
year={2021},
publisher={Springer}}
Unsupervised deep context prediction for background estimation and foreground segmentation (MVA, 2019)
Abstract:
Model Diagram
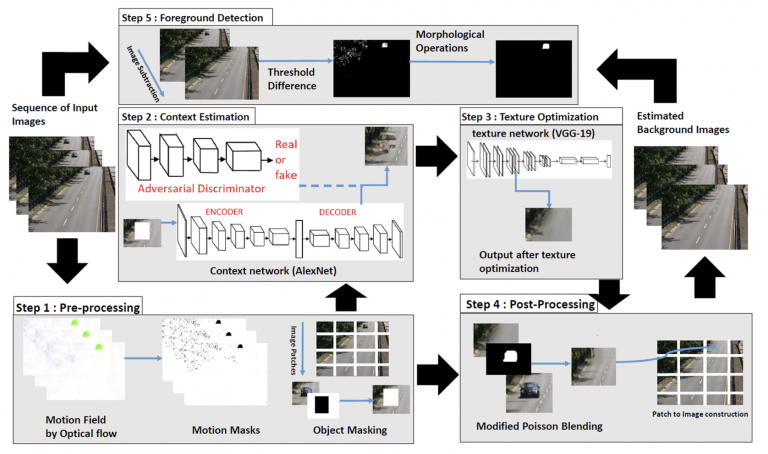
Paper Link:
Citation:
@article{sultana2019unsupervised,
title={Unsupervised deep context prediction for background estimation and foreground segmentation},
author={Sultana, Maryam and Mahmood, Arif and Javed, Sajid and Jung, Soon Ki},
journal={Machine Vision and Applications},
volume={30},
pages={375–395},
year={2019},
publisher={Springer}
}
Action recognition in poor quality spectator crowd videos using head distribution based person segmentation (MVA, 2019)
Abstract:
Paper Link:
Citation:
@article{mahmood2019action,
title={Action recognition in poor-quality spectator crowd videos using head distribution-based person segmentation},
author={Mahmood, Arif and Al-Maadeed, Somaya},
journal={Machine Vision and Applications},
volume={30},
number={6},
pages={1083–1096},
year={2019},
publisher={Springer}}
Canny edge detection and Hough transform for high resolution video streams using Hadoop and Spark (CC, 2019)
Abstract:
Model Diagram
Paper Link:
Citation:
@article{iqbal2020canny,
title={Canny edge detection and Hough transform for high resolution video streams using Hadoop and Spark},
author={Iqbal, Bilal and Iqbal, Waheed and Khan, Nazar and Mahmood, Arif and Erradi, Abdelkarim},
journal={Cluster Computing},
volume={23},
number={1},
pages={397–408},
year={2020},
publisher={Springer}
}
A Boosting Framework for Human Posture Recognition Using Spatio-Temporal Features along with Radon Transform (MTA, 2022)
Abstract:
Model Diagram
Paper Link:
Citation:
@article{aftab2022boosting,
title={A boosting framework for human posture recognition using spatio-temporal features along with radon transform},
author={Aftab, Salma and Ali, Syed Farooq and Mahmood, Arif and Suleman, Umar},
journal={Multimedia Tools and Applications},
volume={81},
number={29},
pages={42325–42351},
year={2022},
publisher={Springer}}
Improving Object Tracking by Added Noise and Channel Attention (Sensors, 2020)
Abstract:
Model Diagram
Paper Link:
Citation:
@article{fiaz2020improving,
title={Improving object tracking by added noise and channel attention},
author={Fiaz, Mustansar and Mahmood, Arif and Baek, Ki Yeol and Farooq, Sehar Shahzad and Jung, Soon Ki},
journal={Sensors},
volume={20},
number={13},
pages={3780},
year={2020},
publisher={MDPI}}
Learning soft mask based feature fusion with channel and spatial attention for robust visual object tracking (Sensors, 2020)
Abstract:
Model Diagram
Paper Link:
Citation:
@article{fiaz2020learning,
title={Learning soft mask based feature fusion with channel and spatial attention for robust visual object tracking},
author={Fiaz, Mustansar and Mahmood, Arif and Jung, Soon Ki},
journal={Sensors},
volume={20},
number={14},
pages={4021},
year={2020},
publisher={MDPI}}
Using temporal covariance of motion and geometric features via boosting for human fall detection (Sensors, 2018)
Abstract:
Paper Link:
Citation:
@article{ali2018using,
title={Using temporal covariance of motion and geometric features via boosting for human fall detection},
author={Ali, Syed Farooq and Khan, Reamsha and Mahmood, Arif and Hassan, Malik Tahir and Jeon, Moongu},
journal={Sensors},
volume={18},
number={6},
pages={1918},
year={2018},
publisher={MDPI}
}
Handcrafted and Deep Trackers: Recent Visual Object Tracking Approaches and Trends (ACM CS, 2019)
Abstract:
Paper Link:
Citation:
@article{fiaz2019handcrafted,
title={Handcrafted and deep trackers: Recent visual object tracking approaches and trends},
author={Fiaz, Mustansar and Mahmood, Arif and Javed, Sajid and Jung, Soon Ki},
journal={ACM Computing Surveys (CSUR)},
volume={52},
number={2},
pages={1–44},
year={2019},
publisher={ACM New York, NY, USA}
}
Visual Object Tracking in the Deep Neural Networks, 2019
Deep Siamese networks towards robust visual tracking
Abstract:
Paper Link:
Citation:
@article{fiaz2019deep,
title={Deep siamese networks toward robust visual tracking},
author={Fiaz, Mustansar and Mahmood, Arif and Jung, Soon Ki},
journal={Visual Object Tracking with Deep Neural Networks},
year={2019},
publisher={IntechOpen London, UK}
}
Video Object Segmentation Based on Guided Feature Transfer Learning (IW-FCV, 2022) [Best Paper Award]
Abstract:
Paper Link:
Citation:
@inproceedings{fiaz2022video,
title={Video Object Segmentation Based on Guided Feature Transfer Learning},
author={Fiaz, Mustansar and Mahmood, Arif and Shahzad Farooq, Sehar and Ali, Kamran and Shaheryar, Muhammad and Jung, Soon Ki},
booktitle={International Workshop on Frontiers of Computer Vision},
pages={197–210},
year={2022},
organization={Springer}
}
Lightweight Encoder-Decoder Architecture for Foot Ulcer Segmentation (IW-FCV, 2022)
Abstract:
Model Diagram
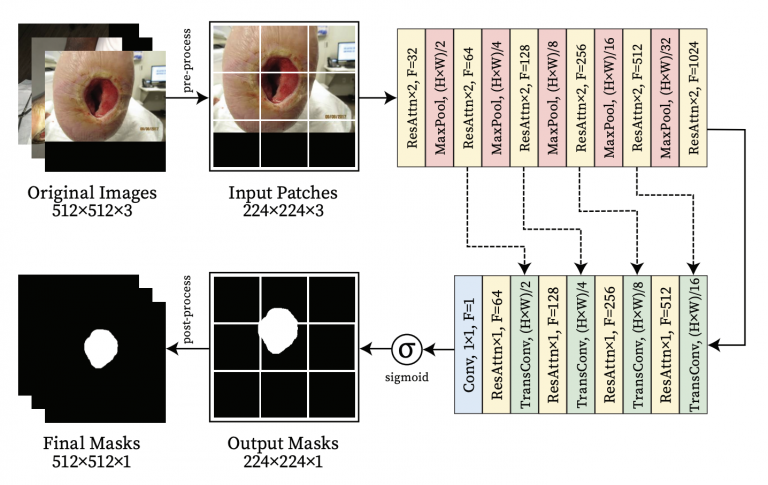
Paper Link:
Citation:
@inproceedings{ali2022lightweight,
title={Lightweight Encoder-Decoder Architecture for Foot Ulcer Segmentation},
author={Ali, Shahzad and Mahmood, Arif and Jung, Soon Ki},
booktitle={International Workshop on Frontiers of Computer Vision},
pages={242–253},
year={2022},
organization={Springer}
}
Robust Tracking via Feature Enrichment and Overlap Maximization (IW-FCV, 2021)
Abstract:
Paper Link:
Citation:
@inproceedings{fiaz2021robust,
title={Robust Tracking via Feature Enrichment and Overlap Maximization},
author={Fiaz, Mustansar and Ali, Kamran and Yun, Sang Bin and Baek, Ki Yeol and Lee, Hye Jin and Kim, In Su and Mahmood, Arif and Farooq, Sehar Shahzad and Jung, Soon Ki},
booktitle={Frontiers of Computer Vision: 27th International Workshop, IW-FCV 2021, Daegu, South Korea, February 22–23, 2021, Revised Selected Papers 27},
pages={17–30},
year={2021},
organization={Springer}
}
Adaptive Feature Selection Siamese Networks for Visual Tracking (IW-FCV, 2020) [Best Student Paper Award]
Abstract:
Model Diagram
Paper Link:
Citation:
@inproceedings{fiaz2020adaptive,
title={Adaptive feature selection Siamese networks for visual tracking},
author={Fiaz, Mustansar and Rahman, Md Maklachur and Mahmood, Arif and Farooq, Sehar Shahzad and Baek, Ki Yeol and Jung, Soon Ki},
booktitle={Frontiers of Computer Vision: 26th International Workshop, IW-FCV 2020, Ibusuki, Kagoshima, Japan, February 20–22, 2020, Revised Selected Papers 26},
pages={167–179},
year={2020},
organization={Springer}
}
Unsupervised Adversarial Learning for Dynamic Background Modelling (IW-FCV, 2020) [Best Paper Award]
Abstract:
Paper Link:
Citation:
@inproceedings{sultana2020unsupervised,
title={Unsupervised adversarial learning for dynamic background modeling},
author={Sultana, Maryam and Mahmood, Arif and Bouwmans, Thierry and Jung, Soon Ki},
booktitle={International Workshop on Frontiers of Computer Vision},
pages={248–261},
year={2020},
organization={Springer}
}
Cross-modal Speaker Verification and Recognition: A Multilingual Perspective (CVPRW, 2021)
Abstract:
Model Diagram
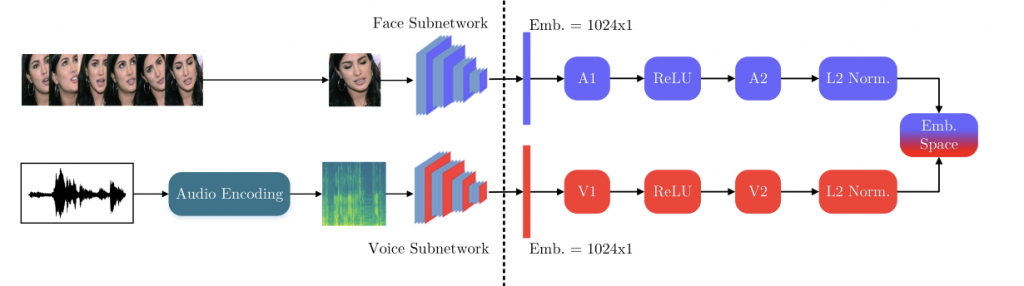
Paper Link:
Citation:
@inproceedings{nawaz2021cross,
title={Cross-modal speaker verification and recognition: A multilingual perspective},
author={Nawaz, Shah and Saeed, Muhammad Saad and Morerio, Pietro and Mahmood, Arif and Gallo, Ignazio and Yousaf, Muhammad Haroon and Del Bue, Alessio},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={1682–1691},
year={2021}
}
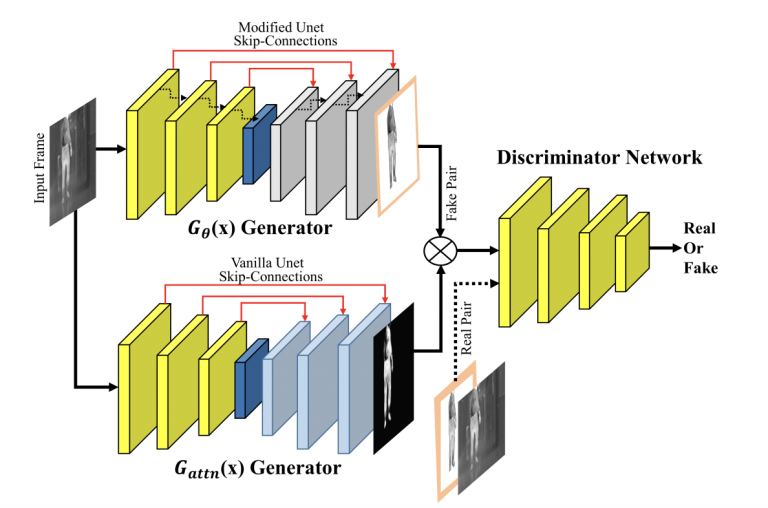
Cleaning Label Noise with Clusters for Minimally Supervised Anomaly Detection (CVPRW - Learning from Unlabeled Videos (LUV2020))
Abstract:
Model Diagram
Paper Link:
Citation:
@article{zaheer2021cleaning,
title={Cleaning label noise with clusters for minimally supervised anomaly detection},
author={Zaheer, Muhammad Zaigham and Lee, Jin-ha and Astrid, Marcella and Mahmood, Arif and Lee, Seung-Ik},
journal={arXiv preprint arXiv:2104.14770},
year={2021}}
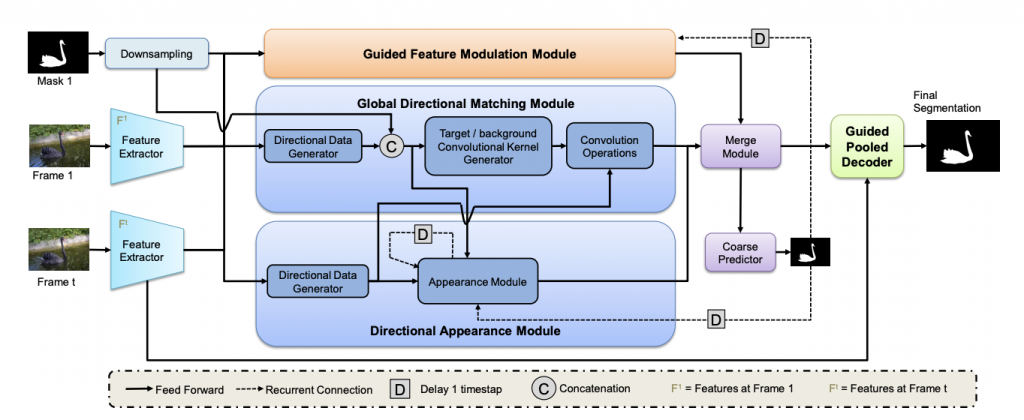
Video Object Segmentation using Guided Feature and Directional Deep Appearance Learning (CVPRW, 2020)
Abstract:
Model Diagram
Paper Link:
Citation:
@inproceedings{fiaz2020video,
title={Video object segmentation using guided feature and directional deep appearance learning},
author={Fiaz, Mustansar and Mahmood, Arif and Jung, Soon Ki},
booktitle={Proceedings of the 2020 DAVIS Challenge on Video Object Segmentation-CVPR, Workshops, Seattle, WA, USA},
volume={19},
year={2020}
}
An anomaly detection system via moving surveillance robots with human collaboration (ICCVW, 2021)
Abstract:
Model Diagram
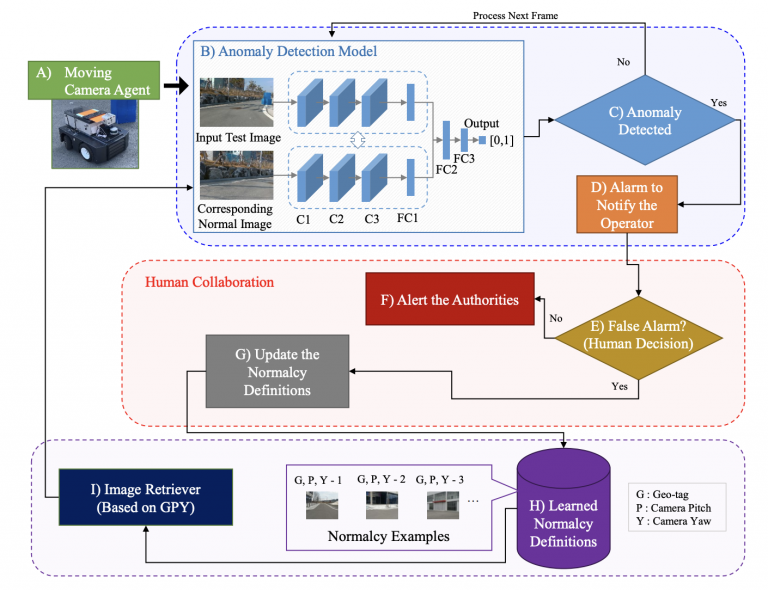
Paper Link:
Citation:
@inproceedings{zaheer2021anomaly,
title={An anomaly detection system via moving surveillance robots with human collaboration},
author={Zaheer, Muhammad Zaigham and Mahmood, Arif and Khan, M Haris and Astrid, Marcella and Lee, Seung-Ik},
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision},
pages={2595–2601},
year={2021}
}
Background/Foreground Separation: Guided Attention based Adversarial Modeling (GAAM) versus Robust Subspace Learning Methods (ICCVW, 2021)
Abstract:
Model Diagram
Paper Link:
Citation:
@inproceedings{sultana2021background,
title={Background/Foreground Separation: Guided Attention based Adversarial Modeling (GAAM) versus Robust Subspace Learning Methods},
author={Sultana, Maryam and Mahmood, Arif and Bouwmans, Thierry and Khan, Muhammad Haris and Jung, Soon Ki},
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision},
pages={181–188},
year={2021}}
Deep Multiresolution Cellular Communities for Semantic Segmentation of Multi-Gigapixel Histology Images (ICCVW, 2019)
Abstract:
Model Diagram
Paper Link:
Citation:
@inproceedings{javed2019deep,
title={Deep multiresolution cellular communities for semantic segmentation of multi-gigapixel histology images},
author={Javed, Sajid and Mahmood, Arif and Werghi, Naoufel and Rajpoot, Nasir},
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops},
pages={0–0},
year={2019}
}
Complete Moving Object Detection in the Context of Robust Subspace Learning (ICCVW, 2019)
Abstract:
Model Diagram
")
Paper Link:
Citation:
@inproceedings{sultana2019complete,
title={Complete moving object detection in the context of robust subspace learning},
author={Sultana, Maryam and Mahmood, Arif and Bouwmans, Thierry and Ki Jung, Soon},
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops},
pages={0–0},
year={2019}}
Do Cross Modal Systems Leverage Semantic Relationships? (ICCVW, 2019)
Abstract:
Model Diagram
Paper Link:
Citation:
@inproceedings{nawaz2019cross,
title={Do cross modal systems leverage semantic relationships?},
author={Nawaz, Shah and Kamran Janjua, Muhammad and Gallo, Ignazio and Mahmood, Arif and Calefati, Alessandro and Shafait, Faisal},
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops},
pages={0–0},
year={2019}
}
Bag of Visual Words Approach for Classification of Benign and Malignant Masses in Mammograms Using Voting Based Feature Encoding (IWBI, 2018)
Abstract:
Model Diagram
Paper Link:
Citation:
@inproceedings{inproceedings,
author = {Suhail, Zobia and Denton, Erika and Zwiggelaar, Reyer and Mahmood, Arif},
year = {2018},
month = {07},
pages = {2},
title = {Bag of visual words based approach for the classification of benign and malignant masses in mammograms using voting-based feature encoding},
doi = {10.1117/12.2316307}
}
Unsupervised RGBD Video Object Segmentation Using GANs (ACCVW, 2018)
Abstract:
Model Diagram
Paper Link:
Citation:
@article{sultana2018unsupervised,
title={Unsupervised rgbd video object segmentation using gans},
author={Sultana, Maryam and Mahmood, Arif and Javed, Sajid and Jung, Soon Ki},
journal={arXiv preprint arXiv:1811.01526},
year={2018}
}
11. M Ghafoor, and Arif Mahmood, “Quantification of Occlusion Handling Capability of 3D Human Pose Estimation Framework.” IEEE Transactions on Multimedia, 2022, (IF 8.182).
10. M Z Zaheer, Arif Mahmood, M H Khan, M Segu, F Yu, S I Lee, “Generative Cooperative Learning for Unsupervised Video Anomaly Detection”, in IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2022.
11. S Javed, Arif Mahmood, J Dias, and N Werghi, “Multi-Level Feature Fusion for Nucleus Detection in Histology Images Using Correlation Filters” Computers in Biology and Medicine, 2022, (IF 6.698).
12. T Hassan, S Javed, Arif Mahmood, T Qaiser, N Werghi, and N Rajpoot, “Nucleus Classification in Histology Images Using Message Passing Network.” Medical Image Analysis, 2022, (IF 13.828).
13. Y Hao, Z Tang, B Alzahrani, R Alotaibi, R Alharthi, M Zhao, and Arif Mahmood, “An End-to-End Human Abnormal Behavior Recognition Framework for Crowds with Mentally Disordered Individuals.” IEEE journal of Biomedical and Health Informatics, 2022, (IF 7.021).
14. S Aftab, S F Ali, Arif Mahmood, and U Suleman, “A Boosting Framework for Human Posture Recognition Using Spatio-Temporal Features along with Radon Transform.” Multimedia Tools and Applications, 2022 (IF 2.577).
15. S Aldhaheri, R Alotaibi, B Alzahrani, A Hadi, Arif Mahmood, A Alhothali, and A Barnawi, “MACC Net: Multi-Task Attention Crowd Counting Network”, Applied Intelligence, 2022, (IF 5.019).
16. M Sultana, Arif Mahmood, and S K Jung, “Unsupervised Moving Object Segmentation Using Background Subtraction and Optimal Adversarial Noise Sample Search”, Pattern Recognition, 2022, (IF 8.518).
17. M Ghafoor, K Javed, and Arif Mahmood, “Walk Like Me: Video to Video Action Transfer” IEEE TechRxiv, 2022.
18. S M Shakeel, Y Zhang, X Wang, W Kang, and Arif Mahmood, “Multi-Scale Attention Guided Network for End-to-End Face Alignment and Recognition” Journal of Visual Communication and Image Representation, 2022, (IF 2.887).
19. J H Giraldo, Arif Mahmood, B Garcia-Garcia, D Thanou, and T Bouwmans, “Reconstruction of Time-Varying Graph Signals via Sobolev Smoothness” IEEE Transactions on Signal and Information Processing over Networks, 2022, (IF 3.301).
20. B Yousaf, M Usama, W Sultani, Arif Mahmood, and J Qadir, “Fake Visual Content Detection Using Two-Stream Convolutional Neural Networks” Neural Computing and Applications, 2022, (IF 5.102).
21. S Javed, Arif Mahmood, I Ullah, and T Bouwmans, “A Novel Algorithm Based on a Common Subspace Fusion for Visual Object Tracking” IEEE Access, 2022, (IF 3.476).
22. R Wang, R Alotaibi, B Alzahrani, Arif Mahmood, G Wu, H Xia, A Alshehri, and S Aldhaheri, “AAC: Automatic Augmentation for Crowd Counting” Neurocomputing, 2022, (IF 5.779).
23. I Ganapathi, S Javed, S S Ali, Arif Mahmood, N S Vu, and N Werghi, “Learning to Localize Image Forgery Using End-to-End Attention Network.” Neurocomputing, 2022, (IF 5.779).
24. M Sultana, Arif Mahmood, T Bouwmans, M H Khan, and S K Jung, “Moving Objects Segmentation Using Generative Adversarial Modeling” Neurocomputing, 2022, (IF 5.779).
25. S Ali, Arif Mahmood, S K Jung, “Lightweight Encoder-Decoder Architecture for Foot Ulcer Seg-mentation” in International Workshop on Frontiers of Computer Vision, Japan, 2022.
26. M Fiaz, Arif Mahmood, S S Farooq, K Ali, M Shaheryar, S K Jung, “Video Object Segmentation Based on Guided Feature Transfer Learning” in International Workshop on Frontiers of Computer Vision, Japan, 2022. [Best Paper Award]
27. S Javed, Arif Mahmood, J Dias, L Seneviratne, N Werghi, “Hierarchical Spatiotemporal Graph Regularized Discriminative Correlation Filter for Visual Object Tracking”, in IEEE Transactions on Cybernetics, 2021. (IF 11.079)
28. J Iqbal, MA Munir, Arif Mahmood, AR Ali, M Ali, “Leveraging orientation for weakly supervised object detection with application to firearm localization”, Neurocomputing, 2021. (IF 4.438)
29. S Javed, Arif Mahmood, N Rajpoot, J Dias, N Werghi, “Spatially Constrained Context-Aware Hierarchical Deep Correlation Filters for Nucleus Detection in Histology Images”, Medical Image Analysis, 2021. (IF 11.48)
30. M Asim, C Brekke, Arif Mahmood, T Eltoft, M Reigstad, “Improving Chlorophyll-a Estimation from sentinel-2 (MSI) in the Barents Sea using Machine Learning”, IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2021. (IF 3.827)
31. W Abbas, MF Khan, M Taj, Arif Mahmood, “Statistically correlated multi-task learning for autonomous driving”, Neural Computing and Applications, 2021. (IF 4.774)
32. M Farooq, M N Dailey, Arif Mahmood, J Moonrinta, M Ekpanyapong, “Human face super- resolution on poor quality surveillance video footage”, Neural Computing and Applications, 2021. (IF 4.774)
33. S Nawaz, M S Saeed, P Morerio, Arif Mahmood, I Gallo, M H Yousaf, “Cross-modal Speaker Verification and Recognition: A Multilingual Perspective”, Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshop, 2021.
34. B Yousaf, M Usama, W Sultani, Arif Mahmood, J Qadir, “Fake Visual Content Detection Using Two-Stream Convolutional Neural Networks”, arXiv preprint arXiv:2101.00676, 2021.
35. M S Saeed, P Morerio, Arif Mahmood, I Gallo, M H Yousaf, “Cross-modal Speaker Verification and Recognition: A Multilingual Perspective”, Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshop, 2021.
36. M Fiaz, K Ali, S B Yun, K Y Baek, H J Lee, I S Kim, Arif Mahmood, S S Farooq, S K Jung, “Robust Tracking via Feature Enrichment and Overlap Maximization”, International Workshop on Frontiers of Computer Vision (IW-FCV) 2021.
37. MZ Zaheer, Arif Mahmood, MH Khan, M Astrid, SI Lee, “An anomaly detection system via moving surveillance robots with human collaboration” in Proceedings of the IEEE/CVF International Conference on Computer Vision Workshop, 2021.
38. M Sultana, Arif Mahmood, T Bouwmans, MH Khan, SK Jung, “Background/Foreground Separation: Guided Attention based Adversarial Modeling (GAAM) versus Robust Subspace Learning Methods”, Proceedings of the IEEE/CVF International Conference on Computer Vision Workshop, 2021.
39. S Javed, Arif Mahmood, K Benes, N Rajpoot, “Multiplex Cellular Communities in Multi-Gigapixel Colorectal Cancer Histology Images for Tissue Phenotyping”, IEEE Transactions on Image Processing (TIP), 2020. (IF 9.340)
40. S Javed, Arif Mahmood, JM Dias, N Werghi, “Robust Structural Low-Rank Tracking” IEEE Transactions on Image Processing (TIP), 2020. (IF 9.340)
41. S Javed, Arif Mahmood, M M Fraz, N A Koohbanania, K Benesc, Y W Tsangc, K Hewittc, D Epsteind, D Sneadc, N Rajpoot, “Cellular Community Detection For Tissue Phenotyping In Colorectal Cancer Histology Images”, Medical Image Analysis (MEDIA), July 2020. (IF 11.48)
42. M Sultana, Arif Mahmood, SK Jung, “Unsupervised Moving Object Detection in Complex Scenes Using Adversarial Regularizations” IEEE Transactions on Multimedia (TMM), 2020. (IF 6.051)
43. M Abdullah, W Iqbal, Arif Mahmood, F Bukhari, A Erradi, “Predictive Autoscaling of Microservices Hosted in Fog Microdata Center”, IEEE Systems Journal, 2020. (IF 3.987)
44. MZ Zaheer, Arif Mahmood, H Shin, SI Lee, “A Self-Reasoning Framework for Anomaly Detection Using Video-Level Labels”, IEEE Signal Processing Letters (SPL), 2020. (IF 3.105)
45. MZ Zaheer, Arif Mahmood, M Astrid, SI Lee, “CLAWS: Clustering Assisted Weakly Supervised Learning with Normalcy Suppression for Anomalous Event Detection”, European Conference on Computer Vision (ECCV), 2020.
46. M Fiaz, Arif Mahmood, KY Baek, SS Farooq, SK Jung, “Improving Object Tracking by Added Noise and Channel Attention” Sensors, 2020. (IF 3.275)
47. M Fiaz, Arif Mahmood, SK Jung, “Learning soft mask based feature fusion with channel and spatial attention for robust visual object tracking” Sensors 20 (14), 2020. (IF 3.275)
48. MZ Zaheer, J Lee, M Astrid, Arif Mahmood, SI Lee, “Cleaning Label Noise with Clusters for Minimally Supervised Anomaly Detection”, Computer Vision Pattern Recognition Workshop (CVPRW), 2020.
49. M Fiaz, Arif Mahmood, SK Jung, “Video Object Segmentation using Guided Feature and Directional Deep Appearance Learning” Computer Vision Pattern Recognition Workshop (DAVIS Challenge), 2020.
50. M Sultana, Arif Mahmood, T Bouwmans, SK Jung, “Dynamic Background Subtraction using Least Squares Adversarial Learning”, IEEE International Conference on Image Processing (ICIP), 2020.
51. S Javed, Arif Mahmood, J Dias, N Werghi, “CS-RPCA: Clustered Sparse RPCA for Moving Object Detection”, IEEE International Conference on Image Processing (ICIP) , 2020.
52. A Basit, MA Munir, M Ali, N Werghi, Arif Mahmood, “Localizing firearm carriers by identifying human-object pairs”, IEEE International Conference on Image Processing (ICIP), 2020.
53. M Asim, C Brekke, Arif Mahmood, T Eltoft, M Reigstad, “Ocean Color Net (OCN) for the Barents Sea”, IEEE International Geoscience and Remote Sensing Symposium (IGRSS), Aug, 2020.
54. M Fiaz, M M Rahman, Arif Mahmood, S S Farooq, K Y Baek, S K Jung, “Adaptive Feature Selection Siamese Networks for Visual Tracking”, International Workshop on Frontiers of Computer Vision (IW-FCV), Ibusuki, Japan, January 2020. (Best Student Paper Award)
55. M Sultana, Arif Mahmood, T Bouwmans, S K Jung, “Unsupervised Adversarial Learning for Dynamic Background Modelling”, International Workshop on Frontiers of Computer Vision (IW- FCV), Ibusuki, Japan, January 2020. (Best Paper Award)
56. N Khan, A Akram, Arif Mahmood, S Ashraf, K Murtaza, “Masked Linear Regression for Learning Local Receptive Fields for Facial Expression Synthesis”, International Journal of Computer Vision (IJCV), September 2019. (IF 6.071)
57. W Iqbal, A Erradi, M Abdullah, Arif Mahmood, “Predictive Auto-scaling of Multi-tier Applications Using Performance Varying Cloud Resources”, in IEEE Transactions on Cloud Computing (TCC), September 2019. (IF 5.967)
58. M S Farid, Arif Mahmood, S Al-Maadeed, “Multi-focus Image Fusion Using Content Adaptive Blurring”, in Information Fusion, January 2019 (IF 10.716)
59. S Javed, Arif Mahmood, S Al-Maadeed, T Bouwmans, S K Jung, “Moving Object Detection in Complex Scene Using Spatiotemporal Structured-Sparse RPCA”, in IEEE Transactions on Image Processing (TIP), February 2019. (IF 6.79)
60. M Shaban, Arif Mahmood, S Al-Maadeed, N Rajpoot “An Information Fusion Framework for Person Localization Via Body Pose in Spectator Crowds”, in Information Fusion, November 2019. (IF 10.716)
61. H Ullah, M Uzair, Arif Mahmood, H Ullah, S D Khan, F A Sheikh “Internal Emotion Classification Using EEG Signal with Sparse Discriminative Ensemble”, in IEEE Access, March 2019. (IF 4.098)
62. M Fiaz, Arif Mahmood, S Javed, S K Jung “Handcrafted and Deep Trackers: Recent Visual Object Tracking Approaches and Trends”, in ACM Computing Surveys, Jan 2019 (IF 5.55)
63. B Iqbal, W Iqbal, N Khan, Arif Mahmood, A Erradi “Canny edge detection and Hough transform for high resolution video streams using Hadoop and Spark”, in Cluster Computing, April 2019 (IF 1.851)
64. M Sultana, Arif Mahmood, S Javed, S K Jung, “Unsupervised deep context prediction for background estimation and foreground segmentation”, in Machine Vision and Applications (MVA), April 2019. (IF 1.788)
65. A Erradi, W Iqbal, Arif Mahmood, A Bouguettaya, “Web application resource requirements estimation based on the workload latent features”, in IEEE Transactions on Services Computing (TSC), May 2019 (IF 5.707)
66. Arif Mahmood, S Al-Maadeed, “Action recognition in poor quality spectator crowd videos using head distribution based person segmentation”, in Machine Vision and Applications (MVA), June 2019 (IF 1.788)
67. M Faiz, Arif Mahmood, S K Jung, “Using Convolutional Neural Network With Structural Input for Visual Object Tracking” in ACM/SIGAPP Symposium on Applied Computing (SAC), Cyprus, April 2019.
68. J Iqbal, M A Munir, Arif Mahmood, A R Ali, M Ali, “Orientation Aware Object Detection with Application to Firearms”, arXiv: 2662045, April 2019
69. M Faiz, Arif Mahmood, S K Jung, “Deep Siamese networks towards robust visual tracking” in “Visual Object Tracking in the Deep Neural Networks Era” IntechOpen Publishers, April 2019 (in Press)
70. S Javid, Arif Mahmood, N Werghi, J M M Dias, “Structural Low-Rank Tracking”, IEEE international conference on Advanced Video and Signal-based Surveillance (AVSS), Taiwan, Taipei, September 2019.
71. M Sultana, Arif Mahmood, T Bouwmans, S K Jung, “Complete Moving Object Detection in the Context of Robust Subspace Learning” in IEEE International Conference on Computer Vision (RSLCV Workshop) 2019, Seoul, South Korea.
72. S Javed, Arif Mahmood, N Werghi, N Rajpoot, “Deep Multiresolution Cellular Communities for Semantic Segmentation of Multi-Gigapixel Histology Images”, in IEEE International Conference on Computer Vision (VRMI Workshop) 2019, Seoul, South Korea.
73. S Nawaz, M K Janjua, I Gallo, Arif Mahmood, A Calefati, F Shafait, “Do Cross Modal Systems Leverage Semantic Relationships?” in IEEE International Conference on Computer Vision (CroMol Workshop) 2019, Seoul, South Korea.
74. S Nawaz, M K Janjua, I Gallo, Arif Mahmood, A Calefati, “Deep Latent Space Learning for Cross- modal Mapping of Audio and Visual Signals” in Digital Image Computing: Techniques and Applications (DICTA) 2019, Perth, Australia.”
75. Arif Mahmood, M Uzair, S Al-Maadeed, “Multi-order Statistical Descriptors for Real-time Face Recognition and Object Classification”, in IEEE Access, 2018 (IF 4.098).
76. I Rida, S Al-maadeed, Arif Mahmood, A Boridane, S Baksi “Palmprint Identification Using an Ensemble of Sparse Representations”, in IEEE Access, 2018 (IF 4.098).
77. S Javed, Arif Mahmood, T Bouwmans, S K Jung, “Spatiotemporal Low-rank Modeling for Complex Scene Background Initialization”, in IEEE Transactions on Circuits and Systems for Video Technology, 2018. (IF 4.046)
78. S Ali, R Khan, Arif Mahmood, M Hassan, M Jeon, “Using temporal covariance of motion and geometric features via boosting for human fall detection”, in Sensors, 2018. (IF 3.031)
79. W Iqbal, A Erradi, Arif Mahmood, “Dynamic workload patterns prediction for proactive auto-scaling of web applications”, in Journal of Network and Computer Applications, 2018. (IF 5.273)
80. M Fiaz, Arif Mahmood, S K Jung “Tracking Noisy Targets: A Review of Recent Object Tracking Approaches”, available online arXiv:1802.03098, 2018.
81. Z Suhail, Arif Mahmood, L Wang, P N Malcolm, and R Zwiggelaar, “A Voting-Based Encoding Technique for the Classification of Gleason Score for Prostate Cancers”, in Medical Image Understanding and Analysis (MIUA), University of Southampton, UK, July 2018.
82. Z Suhail, Arif Mahmood, E R E Denton, R Zwiggelaar, “Bag of Visual Words Approach for Classification of Benign and Malignant Masses in Mammograms Using Voting Based Feature Encoding”, in International Workshop on Breast Imaging (IWBI), Atlanta, Georgia, USA, July 2018.
83. M Sultana, Arif Mahmood, S Javed, S K Jung, “Unsupervised RGBD Video Object Segmentation Using GANs”, in ACCV Workshop on RGBD-Sensing and Understanding via Combined Color and Depth, Perth, Australia, December 2018.
Superpixels based Manifold Structured Sparse RPCA for Moving Object Detection (International Workshop on Activity Monitoring by Multiple Distributed Sensing, 2017)
Abstract:
Paper Link:
Citation:
@inproceedings{javed:hal-01580053,
TITLE = {{Superpixels based Manifold Structured Sparse RPCA for Moving Object Detection}},
AUTHOR = {Javed, Sajid and Mahmood, Arif and Bouwmans, Thierry and Soon, Ki Jung},
URL = {https://hal.science/hal-01580053},
BOOKTITLE = {{International Workshop on Activity Monitoring by Multiple Distributed Sensing, 2017}},
ADDRESS = {Londres, United Kingdom},
YEAR = {2017} }